
If you’ve seen us at any trade shows in the first half of 2025 you may have seen some model cars on our booth. This was part of an exciting demo we’ve been showing off giving a glimpse into the future of AI at the edge. Our demo features a diorama of a parking lot monitoring system, with a camera capturing images inside it, then an object detector identifying each vehicle and passing cropped images to an on-device Vision Language Model (VLM) that describes the car.
Joining forces with Qualcomm Technologies has brought us some compelling new hardware with powerful hardware acceleration from the Qualcomm Dragonwing™ range. Our first fully supported target is the Dragonwing 6490 chip, which offers 12 TOPS of AI processing available in its Hexagon NPU. Things get even more exciting with the upcoming Dragonwing IQ9 series chips, providing up to 100 TOPS (an M1 Macbook Pro, for comparison, has an NPU with 11 TOPS).
When you’re working with 100 TOPS, you’re faced with an important question: “What do we do with all this extra power?” We initially launched Edge Impulse to support model creation on the very smallest of microcontrollers, with vision models that will run in under 100Kb of RAM; with this new class of highly accelerated CPU+NPU targets many of the normal restrictions we work with no longer apply. Combine this new powerful hardware with the huge strides being taken with small generative AI models and you get a glimpse into where AI at the edge is going.
Demo Overview
The aim for this demo was to showcase what can be done with the powerful upcoming Dragonwing IQ9 EVK through model cascading, where multiple models are used in sequence to create a powerful overall system. The use-case here was for parking lot management, showing how edge AI could be used to provide vehicle tracking and metadata collection. Here is an architecture diagram of the technologies used:
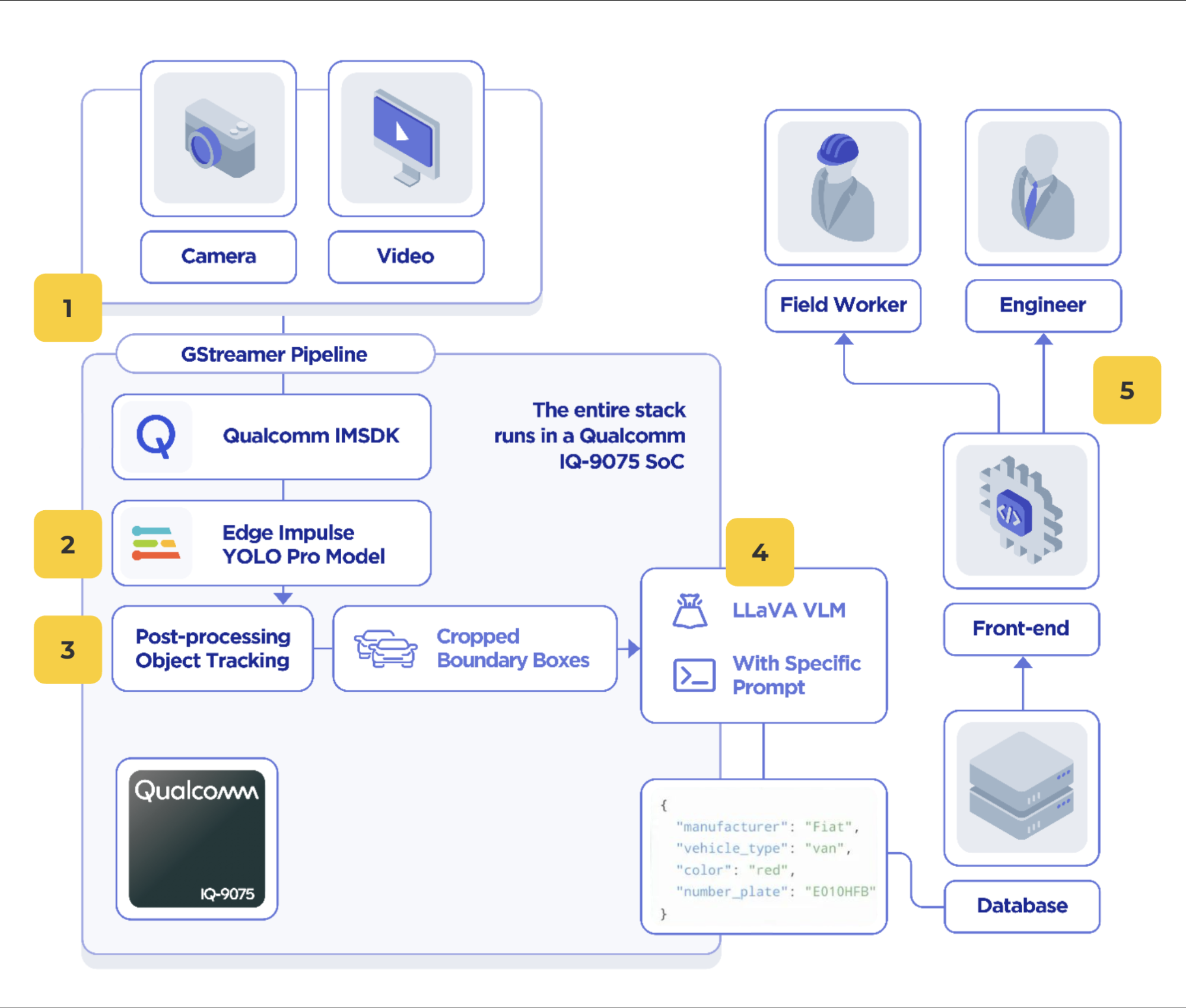
- Camera Acquisition with IMSDK — The IQ9 has support for hardware accelerated gstreamer pipelines, which handle the ingestion and conversion of video streams. Here we collect images from a high resolution camera and pass them through the IMSDK to our object detection model.
- Edge Impulse YOLO Pro — The first model stage is to detect vehicles in the whole image. This is done with a model trained in Edge Impulse using the upcoming YOLO Pro model architecture, our own industrial-focused YOLO-style architecture
- Post Processing — Using our brand new post-processing algorithm for object tracking we follow vehicles within the frame to ensure the high-powered model is only called when a new vehicle is detected.
- LLaVa Vision Language Model — The detected vehicle is then passed to an on-device vision language model for zero-shot classification using a special prompt. Here are some more details:
- Input — By cropping the source image down to just the vehicle we are interested in, the reliability of the VLM is increased. The current generation of on-device VLMs are much smaller and less capable than their cloud counterparts, restricting the input size can help improve this.
- Structured Prompt and Output — We built the prompt using stages with clear options and restricted the output to key, value pairs. This made testing and validating the performance of our prompt on a real dataset possible:
Input Example:
{
"prompt": "Please analyze the provided image of a vehicle in a parking lot and respond to the following questions: ",
"response_type": "context",
},
{
"prompt": "What color is this vehicle?",
"response_type": "free_text",
"response_key": "color",
},
{
"prompt": "What class is this vehicle?",
"response_type": "multiple_choice",
"response_key": "class",
"response_options": [
"van",
"car",
"truck"
]
},
{
"prompt": "Who manufactured this vehicle?",
"response_type": "free_text",
"response_key": "manufacturer",
}
Output Example:
{
"manufacturer": "Fiat",
"vehicle_type": "van",
"color": "red",
}Beyond Inference — In our demo we showed a live UI on a screen, but a production implementation would integrate the model output into the wider parking lot management system. Having structured and predictable outputs from the model make this possible.
Coming soon
This demo is a look to the future of edge AI; we are still working on how best to integrate VLM deployment into the Edge Impulse workflow, so stay tuned for updates on when you can try this out for yourself on real edge hardware. The key learnings from our investigation into VLM technology are:
- Hallucination is even more risky when deploying at the edge; models are smaller and use-cases are often more “mission critical.” Testing and validating that your prompt provides reliable and trustworthy results is critical.
- Model cascading makes sense with powerful hardware — running a “cheap” smaller model continuously and then waking up your high powered model to add context when required saves energy and reduces overall latency.
- Generative AI models are only as good as the data they are trained on (just like any model!). Choosing a VLM to solve your problem is wise when the context is familiar. The internet is full of vehicle information and images, so the VLM is good at solving this problem because it has been trained on this information. Using a VLM for highly specific tasks (without fine-tuning of the base model) is risky.
If you want to start playing with local VLMs you can run the LLaVa model on your laptop or desktop using a tool called Ollama. Combine this with our python library runner and an Edge Impulse model as the start of your model cascade and you’ll have a powerful system!
Sign up for Edge Impulse for free today to start building your first edge AI models and to keep up to date with the latest features and releases.