
Visual anomaly detection focuses on identifying deviations from the norm within visual data. This process involves training algorithms to recognize patterns or features within images or videos and then flagging any instances that deviate from these learned patterns. The anomalies detected could be anything from defects in manufactured goods to unusual activity in surveillance footage. The core idea is to automate the inspection process, allowing for quicker and more accurate identification of issues that might be missed by human observers.
Building a visual anomaly detection pipeline is a complex task, given the variety of approaches that are available and the specific requirements of different applications. One must select an appropriate model architecture, for example, whether it be a convolutional neural network, an autoencoder, a Gaussian mixture model, or otherwise. Each of these choices impacts the effectiveness and efficiency of the anomaly detection system.
In many cases, the anomaly detector has real-time processing constraints that require it to run on edge computing hardware. However, optimizing these algorithms for deployment on such devices introduces additional challenges. Edge devices, such as smartphones, microcontrollers, or IoT devices, have limited computational resources and energy budgets. Given the computationally intensive nature of visual anomaly detection algorithms, ensuring they run efficiently on these devices without compromising performance is a significant hurdle. A number of strategies exist, such as model compression, quantization, and the use of specialized hardware accelerators, but implementing these strategies is no small task.

To help make sense of the available options, Mathieu Lescaudron has compiled a detailed survey of available model architectures, training platforms, and edge deployment options. The work covers topics ranging from dataset creation to model selection and the development of a web app for running inferences. In addition to providing detailed instructions for getting different types of anomaly detection systems off the ground, Lescaudron also compares each of the options to help developers choose the best one for their unique use case.
To kick things off, Lescaudron begins by giving some tips for creating a dataset, which is the starting point for the development of any modern anomaly detection pipeline. Lescaudron kept things simple and used a smartphone to capture a few hundred images of three different types of cookies, some intact, and others with a variety of defects (some more challenging to recognize than others). He then leveraged ImageMagick to reduce the size of the images. This is a crucial step — reducing image size minimizes the amount of computational resources that are needed for downstream processing steps (however, too great of a size reduction can negatively impact detection performance). Of course, one can substitute any other item of interest in the place of cookies to support their own application, such as pills for pharmaceutical use.
Once the dataset is in hand, the next step involves selecting and training an appropriate model. Lescaudron selected a variety of options to support different needs — the fine-tuning of a pre-trained MobileNet model, an EfficientAD algorithm, and Edge Impulse’s innovative FOMO-AD anomaly detector that is specially designed for efficient execution on edge computing platforms.
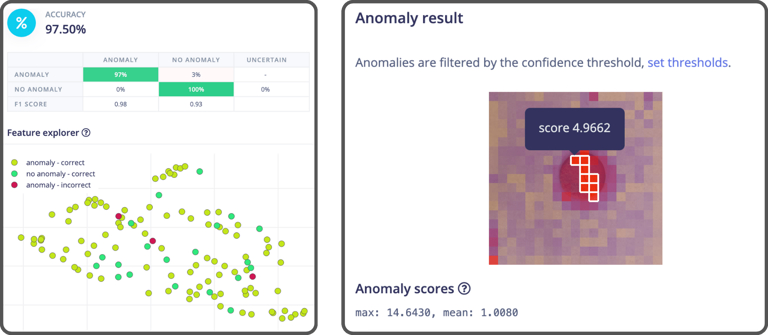
Lescaudron selected MobileNet to serve as the baseline model, as it has been widely used and is well characterized in the literature. The model was configured to recognize “anomaly” or “no anomaly” states, then was trained locally on a laptop computer with TensorFlow using its CPU. The trained model was then converted into a format for use with Edge Impulse via the Edge Impulse Python SDK. By leveraging the Bring Your Own Model feature, Edge Impulse’s tools could then be used to optimize and deploy the MobileNet model.
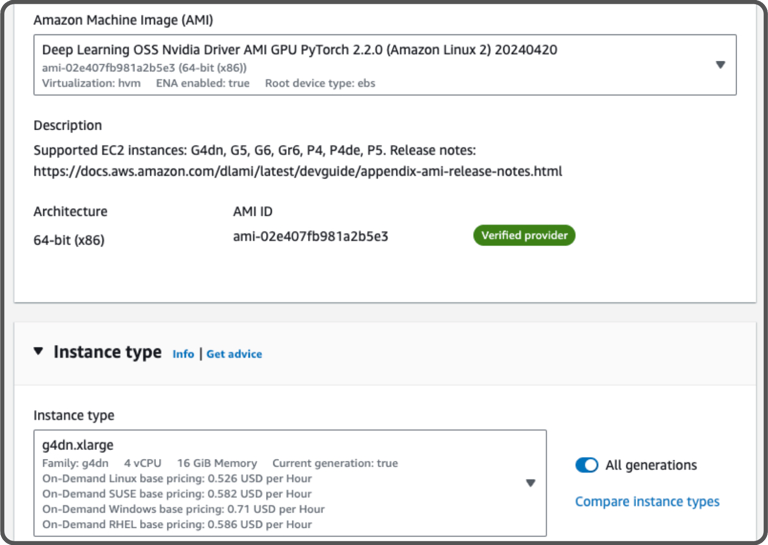
EfficientAD is a cutting-edge model that utilizes an autoencoder paired with a student-teacher approach to efficiently detect anomalies. But to get good results with EfficientAD, a number of hyperparameter values must be selected prior to training. For this purpose, MLFLow was used to automate the testing process while logging the parameters and storing the results. Once appropriate settings were found, the model was trained on a virtual machine in AWS. In particular, a g4dn.xlarge instance with an NVIDIA Tesla 4 GPU was selected. Since EfficientAD has a fundamentally different architecture from a MobileNet classifier, only the images without anomalies were needed for training.
Last, but certainly not least, Lescaudron tested FOMO-AD. Since this algorithm is natively supported by Edge Impulse, the entire process, from uploading data to training, optimizing, and deploying the model could be fully automated with the Edge Impulse API. The pipeline will automatically find the best visual anomaly detection model for the given dataset automatically, eliminating the need for a tool like MLFlow. As was the case with EfficientAD, FOMO-AD does not need anomalies in the training dataset. This factor saves a lot of time and effort when compiling the dataset.
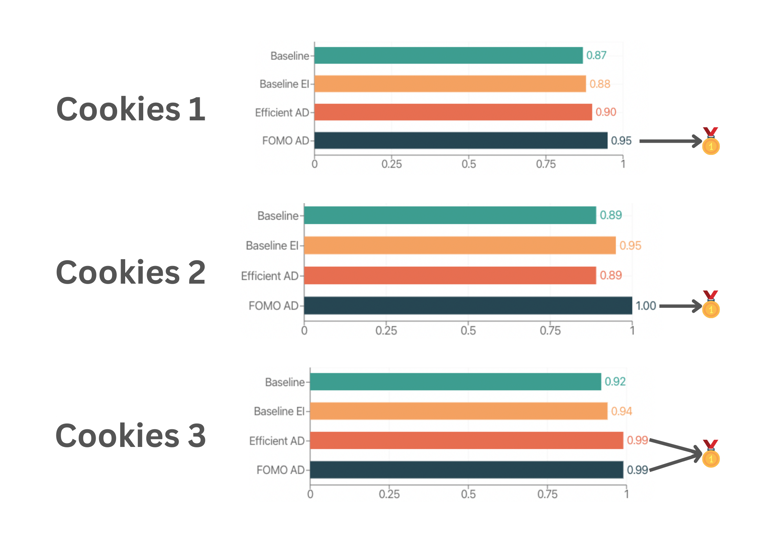
Having trained all of the model options, Lescaudron did some benchmarking to determine which ones performed the best. In each case (no anomaly, or an anomaly of varying degrees), FOMO-AD proved to perform the best as measured by the reported F1 score. FOMO-AD also proved to be the most efficient — inference times were almost ten times faster than what was observed with EfficientAD. These findings, in conjunction with the ease with which FOMO-AD pipelines can be produced, mean that it is generally the best option for most applications.
Once an anomaly detection pipeline is ready for use, some type of interface to put it to work must be developed. Lescaudron demonstrated a few options for building a web-based application for this purpose. For EfficientAD, a serverless endpoint was created using SageMaker Serverless Inference. Behind SageMaker, the tech stack includes Amazon CloudFront and API Gateway, as well as AWS Lambda to serve up the model. SageMaker then runs a Docker container that executes the inferences. This option proved to be quite slow — about 12 seconds per inference — which would exclude it from use in most real-world applications.
Lescaudron also evaluated Edge Impulse’s “Launch in Browser” feature, which allows for real-time testing of a model. Since this feature has been open-sourced and the web assembly code has been made publicly available, it can be used to build custom applications. And since it does not rely on a number of tools in remote locations, as was the case with SageMaker, the inferences are fast enough for use in production applications.
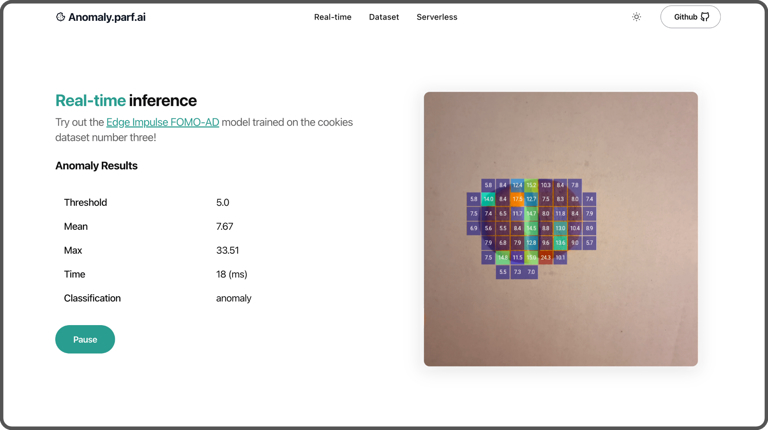
To put the finishing touches on the project, Lescaudron built a website using Astro with React and the AstroWind template. This website provides an interface to run inferences with either EfficientAD or FOMO-AD. It also provides tools to explore the dataset and evaluate the models.
It was noted that performance of the anomaly detectors could be improved by adding synthetic data to produce larger, more diverse training datasets. But however you happen to collect the dataset, be sure to read the full project write-up for some great tips. They will help you to choose the right visual anomaly detection system for your own unique use case, and to get it off the ground quickly.