
The Edge Impulse Python SDK allows you to profile and deploy your machine learning (ML) models that were developed in nearly any ML framework to a number of hardware targets. Such targets include TensorFlow Lite, TensorFlow Lite Micro (TFLM), EON Compiler, vendor-specific toolchains (e.g. TensorRT), and exotic silicon (e.g. Brainchip neuromorphic processor). This SDK wraps the model with a number of useful pre- and post-processing functions along with device specific optimizations and configurations to make deployment as simple as possible.
The TensorFlow ecosystem is well known for the strength and maturity of its deployment tooling. TensorFlow developers are able to easily deploy models for inference almost anywhere, from cloud environments to mobile phones. Most recently, TFLM has enabled developers to deploy to embedded systems, which require efficient, portable code that can be run on simple devices that run at the edge.
Another key part of the TensorFlow ecosystem is its support for MLOps tooling. Edge Impulse is an MLOps tool designed for developers who are creating models for deployment to embedded systems. This post will show you how you can use TensorFlow with Edge Impulse to rapidly deploy a model using TensorFlow Lite for Microcontrollers. Specifically, it will guide you through the process of training a simple model on TensorFlow with Keras and converting that model to a C++ library that integrates TFLM. We’ll do all of this from Python, using the Edge Impulse Python SDK.
The generated C++ library allows you to run inference with TFLM on nearly any device, including microcontrollers, assuming you have a C++ compiler for that hardware. However, the library contains more than just TFLM; it processes the input and output for you, for example by windowing and resampling time series or audio inputs. It also performs post-processing, such as running a moving average filter on a stream of classifier outputs or performing non-maximum suppression on the output of box regression object detection architectures like SSD and YOLO.
Additionally, the library uses macros to automatically apply the appropriate optimizations for the processor you are targeting, whether it’s Arm’s CMSIS-NN, Himax WE-I, etc. For deep learning accelerators that do not support TFLM (such as neuromorphic processors) you can also convert a TF model directly into a compatible package, for example BrainChip AKD1000, Ethos-U55 microNPU, and Syntiant NDP.
This post will also show you how to estimate RAM, ROM, and inference execution time for a hardware family, which can aid in the design flow of a model architecture for edge machine learning (ML). The ability to deploy a model to TFLM via a Python library makes it easy for ML engineering and embedded systems teams to collaborate and quickly iterate while developing edge ML applications.
Introduction
Edge Impulse API
Everything in the Edge Impulse Studio can be scripted using a web API. This allows ML practitioners to build entire pipelines for data collection, training, and deployment for edge devices. To make this process even easier, Edge Impulse maintains a Python SDK so that you can profile and deploy trained models programmatically.
As we’ll see, this SDK is designed for easy integration with TensorFlow ecosystem: it directly supports profiling and deployment of Keras model instances, the TensorFlow SavedModel format, and even JAX models that have been serialized to the SavedModel format.
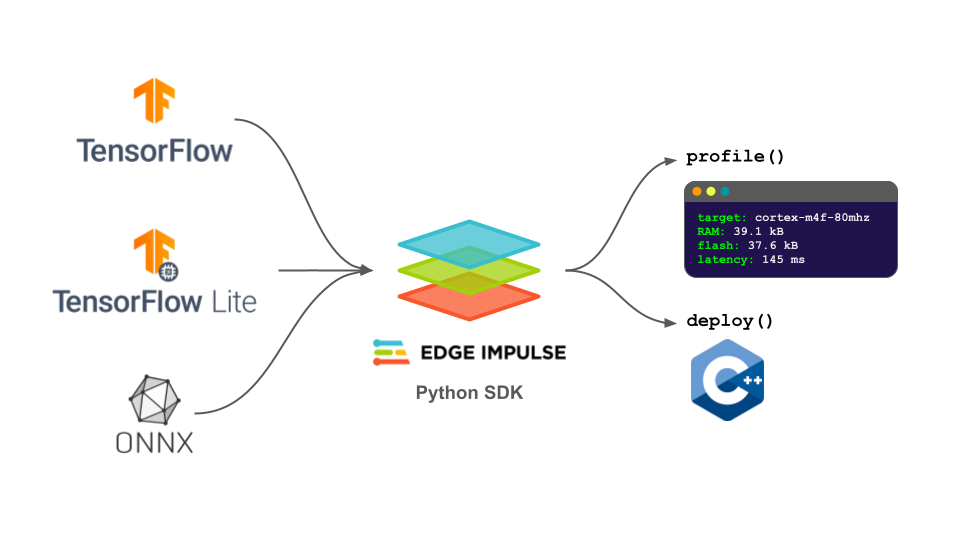
Why TensorFlow and Edge Impulse?
Much of the functionality of Edge Impulse is built using TensorFlow technology. If you switch to “Expert Mode” for training in the Edge Impulse Studio, you can modify the TensorFlow and Keras code to construct your own model architecture and change the way training works. Additionally, Edge Impulse allows you to deploy a trained model to a library that makes use of TensorFlow Lite for Microcontrollers.
Developers can choose to either develop TensorFlow models within Edge Impulse’s web user interface or in their own Python training scripts and notebooks.To support the latter case, the Edge Impulse Python SDK can be used to seamlessly integrate the TensorFlow workflow of model training with profiling and deployment to edge devices. Such target edge devices include hardware that may or may not be supported by TensorFlow Lite and TFLM, such as traditional microcontrollers along with specialized processors (e.g. Brainchip neuromorphic processor). The rest of this article will demonstrate this process.
Train a simple model
To begin, we need a trained model. Luckily, TensorFlow and Keras make that process very easy. Start by installing the necessary dependencies:
python -m pip install edgeimpulse tensorflowFrom there, we train a very simple convolutional neural network (CNN) on the MNIST dataset:
from tensorflow import keras
Settings
labels = ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]
num_classes = len(labels)
Load MNIST data
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = keras.utils.normalize(x_train, axis=1)
x_test = keras.utils.normalize(x_test, axis=1)
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
input_shape = x_train[0].shape
Build the model
model = keras.Sequential([
keras.layers.Flatten(),
keras.layers.Dense(32, activation=’relu’, input_shape=input_shape),
keras.layers.Dense(num_classes, activation=’softmax’)
])
Compile the model
model.compile(optimizer=’adam’,
loss=’categorical_crossentropy’,
metrics=[’accuracy’])
Train the model
To be sure that our model is working properly, we can test it on our holdout set:
# Evaluate model on test set
score = model.evaluate(x_test, y_test, verbose=0)
print("Test loss:", score[0])
print("Test accuracy:", score[1])At this point, we are ready to use the Edge Impulse Python SDK to profile and deploy the model!
Profiling
One tricky part of working with edge deep learning is ensuring that your model fits within the memory constraints, such as RAM and ROM, of your target hardware. Additionally, verifying that the device can perform inference at a speed meeting your specific requirements is critical. For example, if you need a processing rate of 10 frames per second and your device takes 500 milliseconds per inference, you will vastly miss your timing deadlines.
The Edge Impulse Python SDK can help profile your model for a number of different target hardware architectures, including low- and high-end microcontrollers, microprocessors, and neural network accelerators. To start, you will need an API key from an Edge Impulse project. The easiest way to do that is to go to edgeimpulse.com, create an account (if you have not done so already), and create a new project. In your new project, head to the Dashboard and click on the Keys tab. Double-click to highlight the API key and right-click to copy.
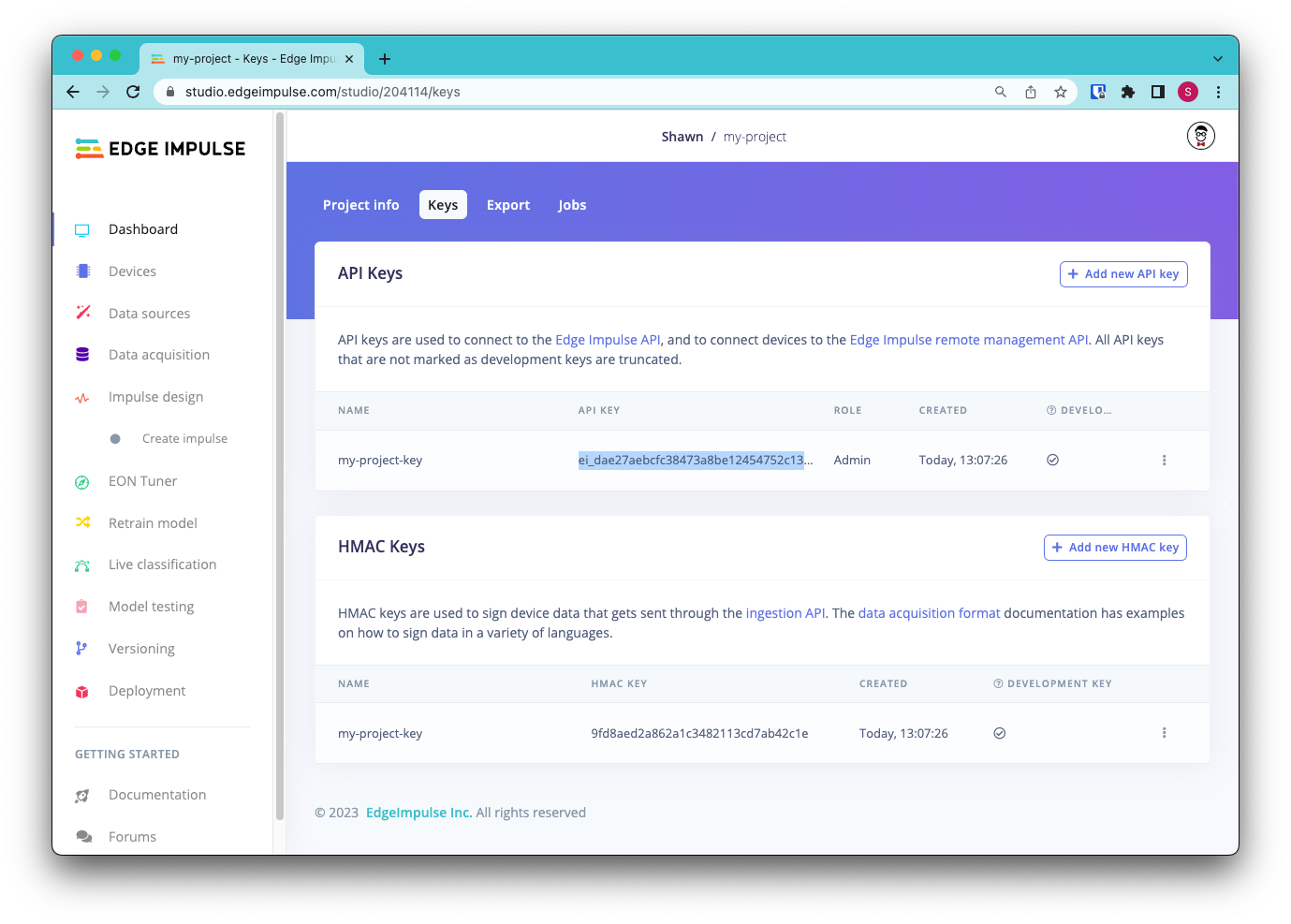
From there, import the Edge Impulse package and set your key.
import edgeimpulse as ei
Change the following to your particular API key
To profile our Keras model, we simply pass in the directory location and provide the target hardware. This produces a string that we can easily read to understand the resource requirements on the device:
# Generate profile for model and print results
results = ei.model.profile(model=model,
device="cortex-m4f-80mhz")
print(results.summary())The RAM, ROM, and timing estimates can be easily parsed and included in your MLOps pipeline to check if your model meets the requirements for your target edge platform. This process can be invaluable when developing an edge ML model within a heavily constrained environment.
Deploying
Once you are happy with the performance of your model and ensure that it meets your resource requirements, you can easily deploy the model using a single function from within the Python SDK. This “deploy” step involves uploading your model to an Edge Impulse project, where it is converted to a C++ library that uses TensorFlow Lite for Microcontrollers. You can see an example of this library (without the model weights themselves) in edgeimpulse/inferencing-sdk-cpp.
We pass the model into the deploy function along with some information about its output:
# Configure model info with class labels
model_output_type = ei.model.output_type.Classification(labels=labels)
Deploy model to C++ library
The function will automatically download a zipped C++ library containing our trained model to the current directory. At this point, you are ready to include the library in your application! This is, of course, assuming your target hardware has an available C++ compiler and enough RAM/ROM for your model (see above for profiling).
We recommend looking through the Edge Impulse documentation for running the C++ library, which contains a number of examples for different hardware platforms.
Conclusion
We hope that the Edge Impulse Python SDK helps you create edge ML applications and construct fully automated edge MLOps pipelines in a familiar environment, while making use of your existing TensorFlow skills. If you would like to learn more about using the Python SDK, please see the getting started guides here.