Today we are delighted to announce that we now support deploying transformers to embedded ML devices!
This is exciting as it was an area previously reserved for deep learning on large-scale datasets producing models too large to deploy on the edge.
Why is this important?
There has been a growing interest in Transformers and their applications to the Edge most recently we noted Georgi Gerganov from ViewRay, Inc. has posted of the “growing interest for doing efficient transformer model inference on-device (i.e. at the edge).” Georgi is well-known for his impressive work porting whisper.cpp and llama.cpp to run on edge devices, which he has published on GitHub.
Transformers have become an indispensable staple in the modern deep learning stack, but they have typically been challenging to deploy to edge devices—until today!
What are transformers?
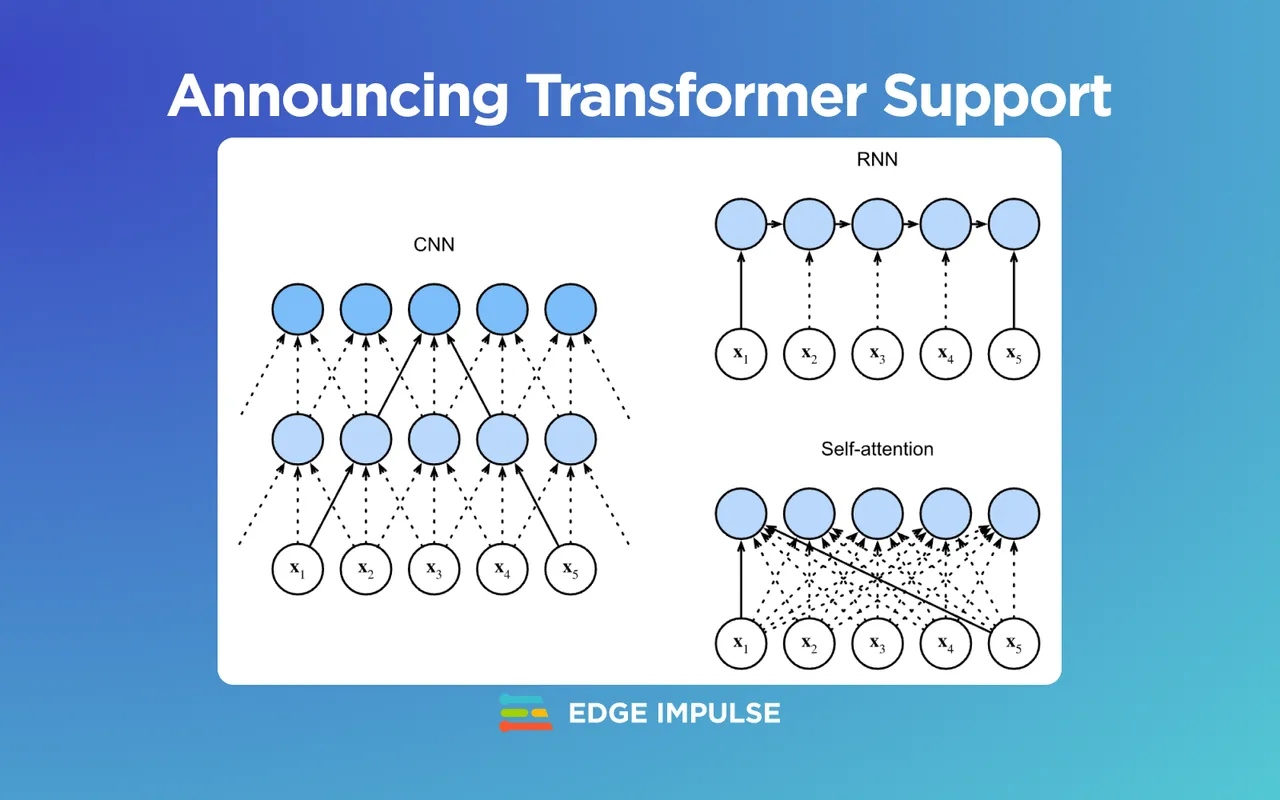
Transformers are powerful and efficient techniques for processing data, pioneered in large-scale NLP applications. They are based on the idea of using a set of self-attention layers to learn to focus on the most relevant features in the data. This makes them well-suited for natural language processing tasks and vision systems.
Transformers can perform similar tasks to Recurrent Neural Networks, through the ability to capture longer-term dependencies in the data by using attention mechanisms which allow the model to focus on specific parts of the input.
Self-Attention works by assigning weights to each part of the input sequence and using those weights to determine which parts of the sequence should be given more importance when making predictions.

Comparing CNN (padding tokens are omitted), RNN, and self-attention architectures. Dive into Deep Learning (2022).
How can I get started?
The key building block of a transformer block is the Keras MultiHeadAttention layer. As part of a recent release we now support this layer. The MultiHeadAttention layer can be used in a variety of tasks, such as natural language processing, image recognition, and time series analysis. Its ability to attend to multiple parts of an input sequence simultaneously makes it particularly useful in tasks where long-term dependencies need to be captured.
To see a working example of timeseries transformers we recommend starting with the public project Created By Naveen Kumar and accompanying blog Fall Detection using a Transformer. Model with Arduino Giga R1 WiFi
To utilize the MultiHeadAttection layer you will need a Classification(Keras) Learn Block and enter Expert Mode. We recommend reviewing the Timeseries classification with a Transformer model example in the Keras documentation. This is the same example Naveen has worked from.
Thanks to our ML team you have access to the building blocks and components used in the Timeseries Transformer model as first described in Timeseries classification with a Transformer model by Theodoros Ntakouris based on material from Attention Is All You Need.
We have run preliminary testing with the Timeseries classification with a Transformer model and are very excited to see what you do with Transformers, as it is such a research led topic that pushes the boundaries on the state-of-the-art.
Please post any questions you have and any projects you create over on our forum or tag @EdgeImpulse on our social media channels!