
Data collection is a critical aspect of machine learning, as the performance and accuracy of models heavily rely on the quality and quantity of the data used for training. However, data collection poses numerous challenges that can hinder the progress of machine learning projects. One significant challenge is obtaining labeled data, particularly in tasks that require extensive human annotation, such as image recognition, natural language processing, or medical diagnosis. Manual labeling can be time-consuming, expensive, and prone to errors, especially when dealing with large datasets.
Another challenge associated with data collection is data scarcity. In certain domains and applications, acquiring a sufficient amount of relevant data for training can be extremely difficult. This limitation is particularly prevalent in specialized fields, novel research areas, or situations where data acquisition is costly, time-consuming, or restricted due to privacy concerns. Without an ample and diverse dataset, machine learning models may struggle to learn complex patterns and correlations, leading to reduced accuracy and poor generalization on unseen data.
Synthetic data offers a compelling solution to the data collection problem by providing artificially generated data that closely mimics the statistical properties and patterns of real-world data. Using sophisticated algorithms and models, synthetic data is created with precise control over its characteristics. Additionally, domain randomization complements the process by intentionally randomizing various parameters and attributes of the data within predefined bounds. This introduces a diverse set of variations that enables the model to become more resilient and versatile, effectively adapting to a wide range of environments and scenarios.
The possibilities that specialized techniques like synthetic data generation can unlock are often left unexplored because putting them into practice can seem daunting to the uninitiated. But truth be told, there are some fantastic tools available that will do most of the heavy lifting for you. There are also some very helpful tutorials on such subjects, like this one recently written by machine learning enthusiast Adam Milton-Barker. In it, Milton-Barker shows how the NVIDIA Omniverse Replicator can complement the Edge Impulse machine learning development platform to create an object detection pipeline that runs on edge computing hardware. And no data collection is required!
The goal of the project is to train an object detection model to recognize different types of fruit, using synthetic data for training. Identifying fruit may not be of particular interest to you, but keep in mind, these same techniques can be used in a wide range of applications. Use cases from autonomous driving and robotics to predictive maintenance and agriculture can make use of synthetic data and object detection to enable new functionalities and create new efficiencies.
The NVIDIA Omniverse Replicator offers a versatile set of APIs that empowers researchers and enterprise developers to create synthetic data closely resembling real-world scenarios. Its highly extensible design allows users to effortlessly build custom synthetic data generation tools, significantly accelerating the training process of computer vision networks.
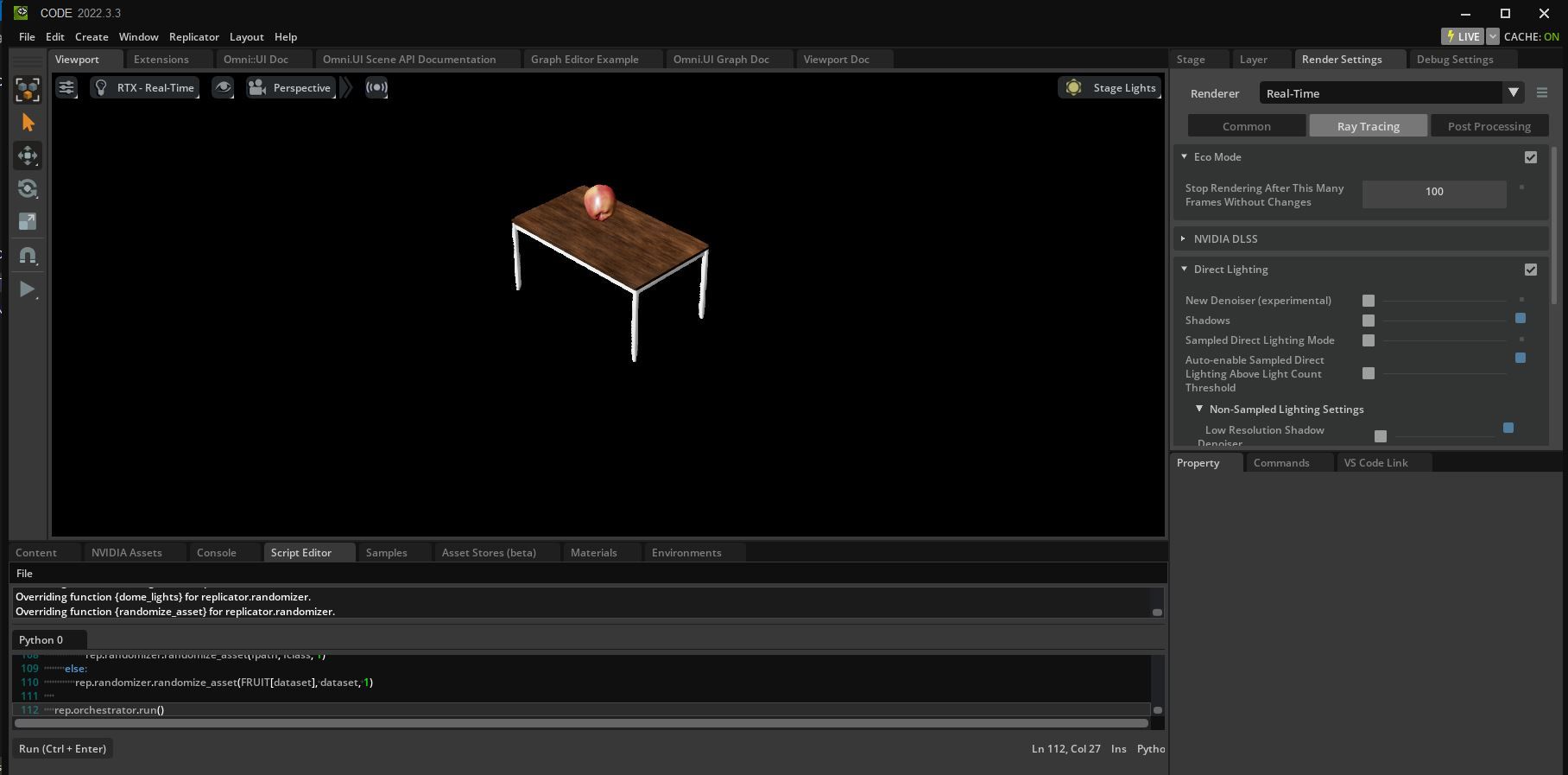
This tool requires an RTX-enabled GPU, which Milton-Barker did not have readily available to him, but fortunately, there are many cloud service providers where one can get access to a suitable virtual machine. After installing NVIDIA Omniverse on this machine, the Universal Scene Description language was used to set up the environment, lighting, camera effects, as well as insertion of fruit into the scenes. Randomizers were also configured so that a diverse set of data would be generated, within some reasonable bounds.
With a photorealistic dataset in hand, Milton-Barker pivoted over to Edge Impulse Studio to build the machine learning object detection pipeline. The ultimate goal was to deploy that pipeline to the tiny, yet powerful NVIDIA Jetson Nano single board computer, so the Jeston was first linked to a project using the Edge Impulse CLI for Linux. This will make it very simple to deploy the trained model when it is ready.
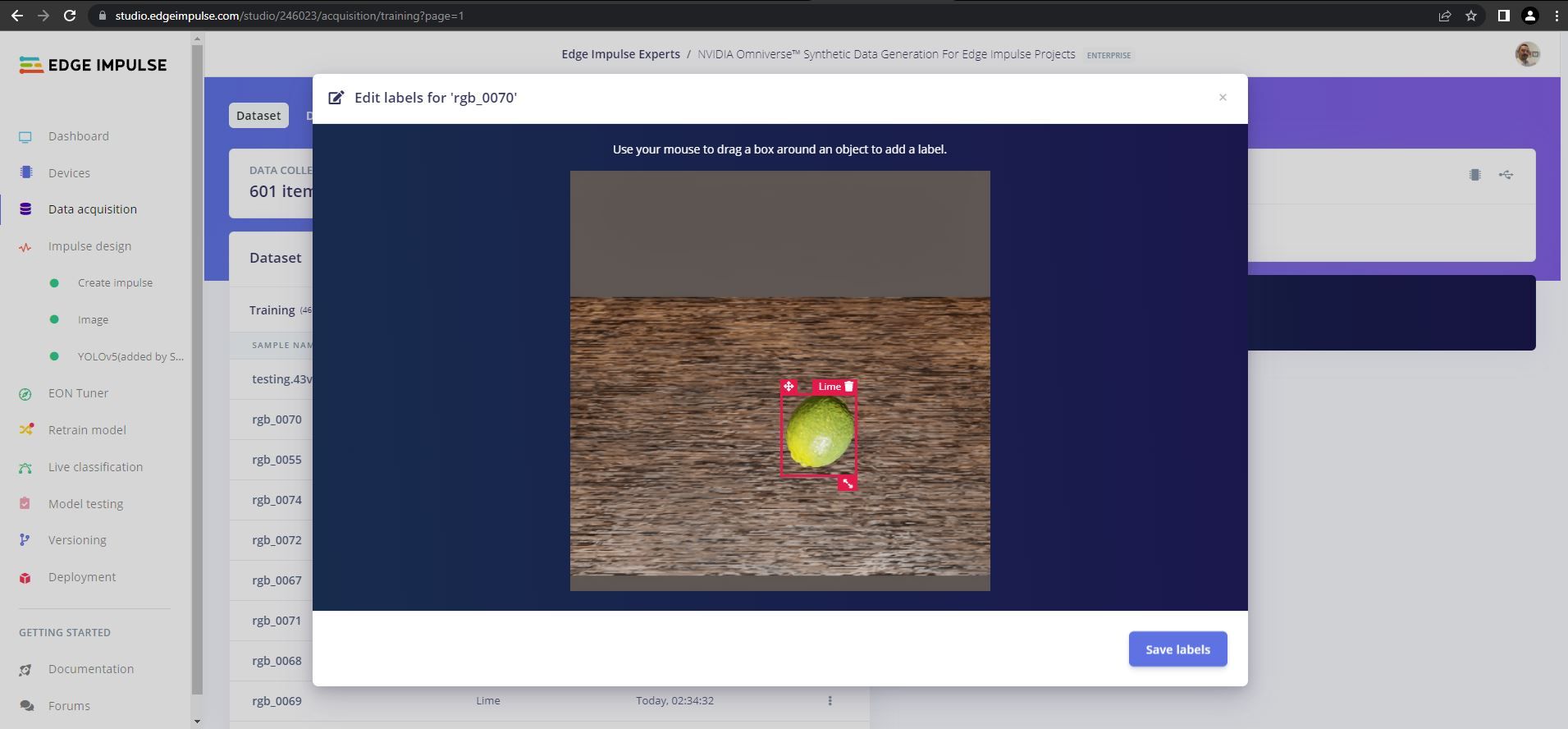
The next step involved uploading and labeling the images using the Data Acquisition tool. At this time, Omniverse represents the bounding boxes that identify objects in a different way than Edge Impulse does, so these boxes needed to be defined again. Fortunately, the Labeling Queue tool offers AI-powered assistance to automatically draw them. It is generally only necessary to make an occasional small update to the bounding box positions.
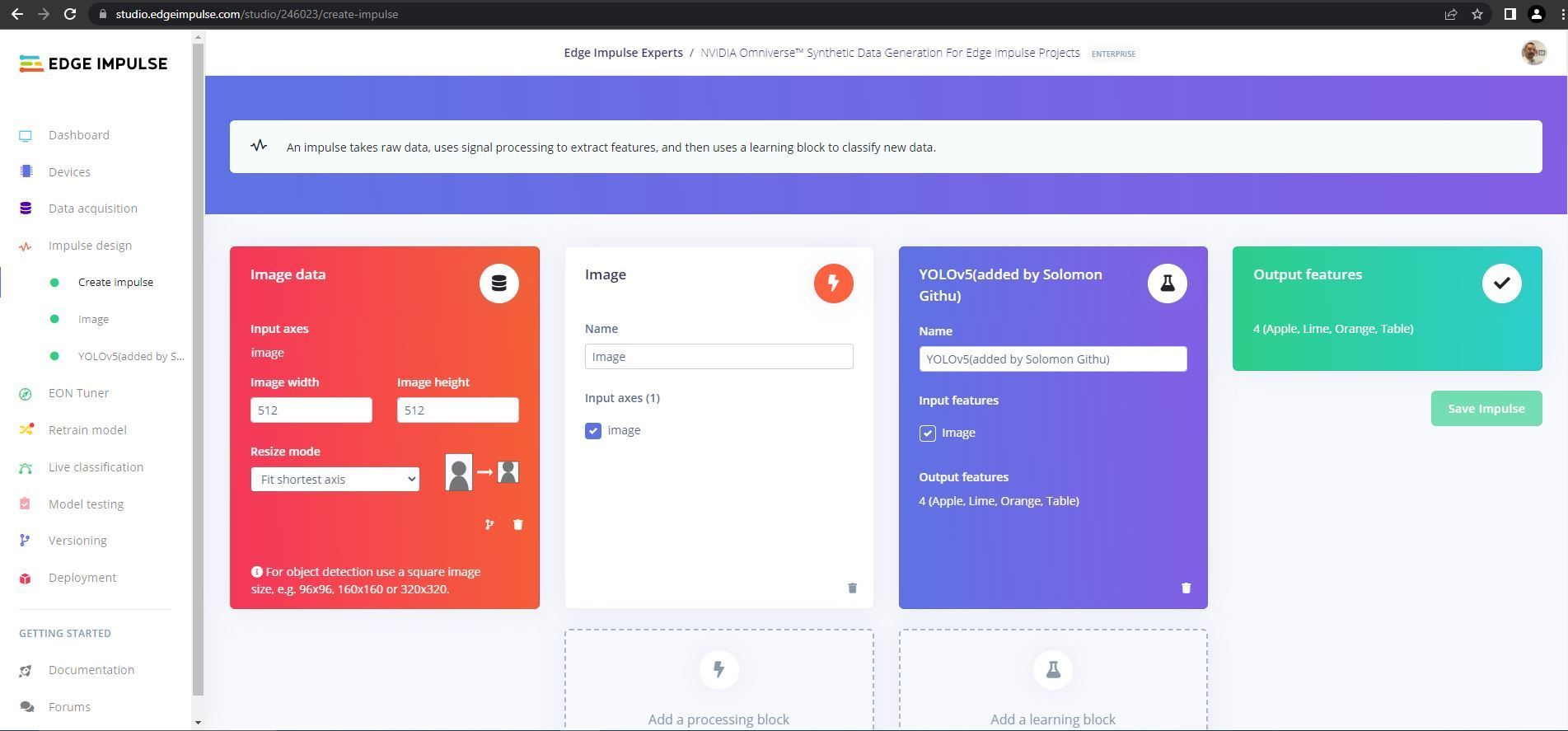
The impulse, which defines the steps that will be taken to process the data, all the way from input images to model predictions, began with a preprocessing step that resizes the images. Bringing down the resolution is an important factor in limiting the hardware resources that the algorithm will require. This was followed by a YOLOv5 object detection model that can recognize apples, oranges, and limes.
Inspecting the data in the Feature Explorer tool showed good clustering of the different classes, which bodes well for the object detector, so Milton-Barker tweaked a few hyperparameters and kicked off the training process. A short time later, metrics were presented to assist in assessing how well the model was doing its job. This showed that a very impressive F1 score of 97.2% had been achieved right off the bat.
It is always wise to validate training results against a dataset that was held out from the training data to ensure that the model has not been overfit to the training data. This can be accomplished using the Model Testing tool, and in this case, it revealed a 99.24% accuracy score. Again, a fantastic result was obtained.
As a final test, the Live Classification tool was used. This captures data from the actual hardware, and will reveal if there are any issues with, for example, the camera or other components that will negatively impact real-world results. After running a few Edge Impulse CLI commands on the Jetson, it was up and running.
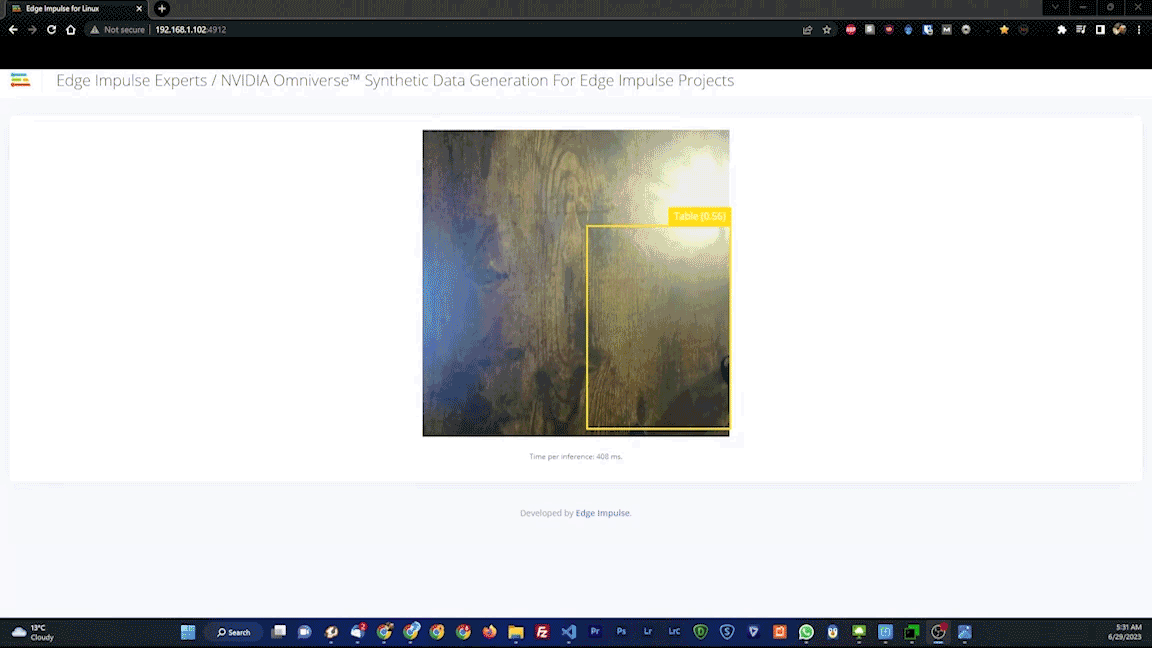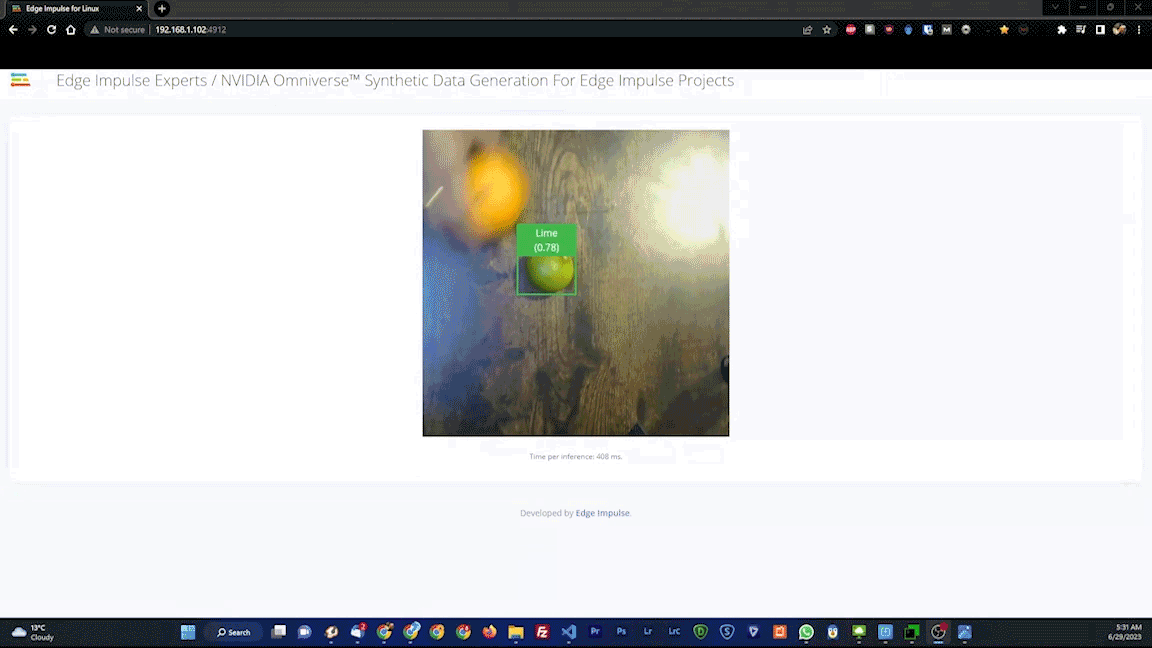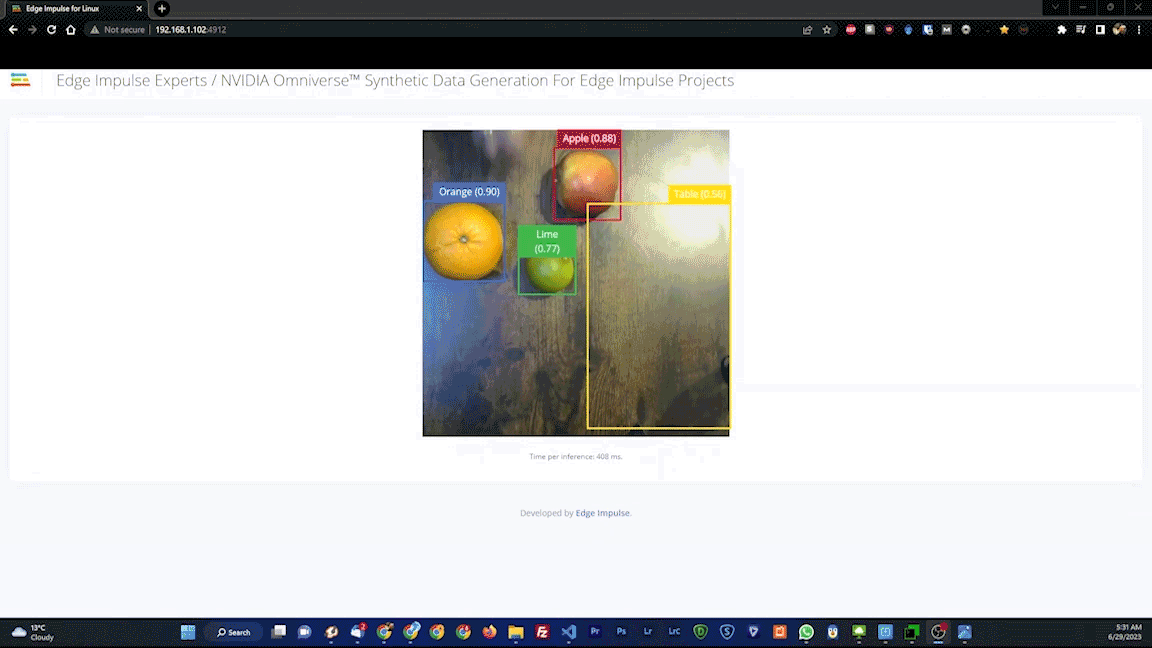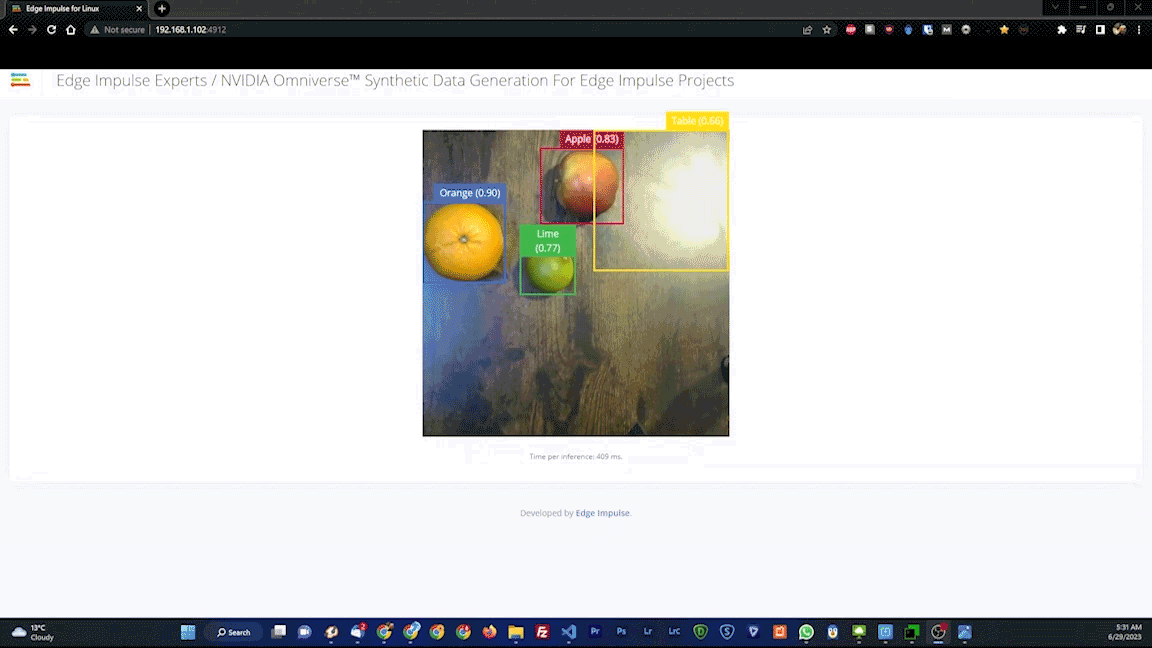
The live test classified fruits as expected, so it was time for deployment of the model to the physical hardware. Again, this just requires a simple command to be executed on the Jetson, then the device is ready to go. No connection to the cloud (or the privacy concerns that can come with it) is required from that point forward.
While the purpose of this exercise was mostly instructive, Milton-Barker notes that some projects utilizing these technologies are on the way in the future. We would love to see what ideas this triggers for you as well. The tutorial and public Edge Impulse Studio project will help you get your ideas off the ground fast. And be sure to discover how you can use NVIDIA Omniverse and Edge Impulse to generate accurate synthetic data to accelerate the training of computer vision AI models for the edge.
Want to see Edge Impulse in action? Schedule a demo today.