Hard to believe, but we managed to make our deployments yet a bit tinier! We've just added a powerful new optimization in the EON™ Compiler helps cut down RAM and flash memory by eliminating duplicate tensor data — automatically.
What is the EON Compiler?
EON Compiler is an umbrella term we use at Edge Impulse for various optimizations we apply to deployments to make them more efficient for resource-constrained devices. At its core, EON Compiler takes a LiteRT (previously Tensorflow Lite) Flatbuffer file containing model weights and outputs a .cpp and .h files containing unpacked model weights and functions to prepare and run the model inference.
Regular Tflite Micro is based on LiteRT (previously Tensorflow Lite) and contains all the necessary instruments for reading the model weights in Flatbuffer format (which is the content of .tflite file), constructing the inference graph, planning the memory allocation for tensors/data, executing the initialization, preparation and finally invoking the operators in the inference graph to get the inference results.
The advantage of using the traditional Tflite Micro approach is that it is very versatile and flexible. The disadvantage is that all the code for getting the model ready on the device is pretty heavy for embedded systems.
To overcome these limitations, our solution involves performing resource-intensive tasks, such as reading the model from Flatbuffer, constructing the graph, and planning memory allocation directly on our servers.
Subsequently, the EON Compiler performs the generation of C++ files, housing the necessary functions for the Init, Prepare, and Invoke stages.
These C++ files can then be deployed on the embedded systems, alleviating the computational burden on those devices.
See the EON Compiler documentation page for more information.
Duplicate tensor data in my model? It's more likely than you think
Since EON Compiler output is .h and .cpp files with the model weights and parameters laid out in plain human-readable format, you can open the .cpp file from any EON compiled C++ deployment and take a look at the content. If you look at an image recognition or object detection model, based on MobileNet, it will not take you much time to notice something interesting.
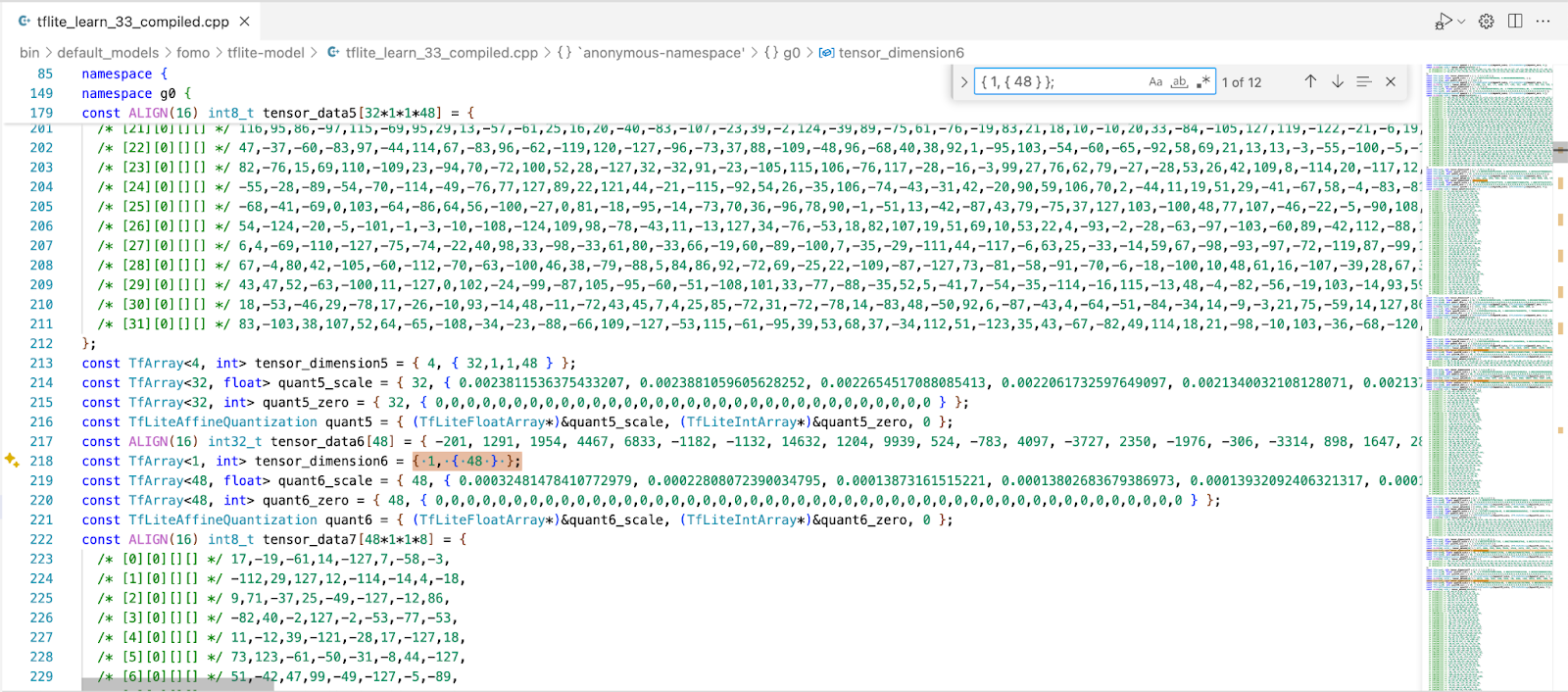
There are a lot of elements that are absolutely THE SAME, for example tensor dimensions or quantization parameters for certain tensors. It makes sense, since MobileNet, as many other popular Neural Network architectures, consists of multiple repeating blocks that are similar or the same. However even though we mark them as const, the C++ compiler is not smart (or simply too cautious) to find and eliminate the duplicates on its own.
How to get rid of duplicate tensor data
To get rid of duplicate tensor data, first we need to find it. Theoretically, we could write an algorithm for manual matching of numbers involved, but in this particular case there is no need to re-invent the wheel. We can use one of the hashing algorithms to find tensor dimensions or quantization parameter arrays that contain identical numbers.
For each tensor property that could be duplicated, the data is serialized into a byte array and passed through a hash function (MD5). The resulting hash string uniquely identifies the data’s contents. By storing these hashes in a map, the compiler can quickly check if an identical array has already been seen: if so, it reuses the existing data instead of emitting a duplicate. This approach ensures that only unique tensor data is included in the generated code, reducing both code size and memory usage without the need for manual or expensive element-by-element comparisons.
Example: Deduplicating Tensor Dimensions
Suppose two tensors have the same shape (e.g., [1, 32, 32, 3]). The compiler serializes this array, computes its hash, and checks the hash map:
- If this shape has already been seen, the tensor’s metadata will point to the existing dimension array.
- If not, the array is emitted as a new constant, and its hash is recorded.
How can you try it
As a rule of thumb, larger vision models benefit more from removing duplicate information, as opposed to smaller models focused on time-series. In our benchmarking, there were 48 (out of 72) duplicate tensor parameters in our standard FOMO model (MobileNetv2 alpha 0.1), removing them saved 10% of both RAM and flash memory.
The best thing is that tensor deduplication is already available to all Edge Impulse users — all the necessary optimizations will be applied if you choose EON Compiler or EON Compiler (RAM Optimized) on model deployment.
Be sure to sign up for a free Developer Plan account today to access this great feature, and many more!