
We are happy to announce the support of multi-label data for time-series datasets in Edge Impulse Studio.
One key improvement with multi-label samples is the enhanced ability to analyze complex datasets. In applications where continuity is important, such as hour-long exercise sessions, sleep studies, or machinery lifecycle stages, this feature allows for maintaining the integrity of longer-duration samples. This approach avoids the need to segment these samples into smaller parts, providing a more adapted view and richer data set for analysis.
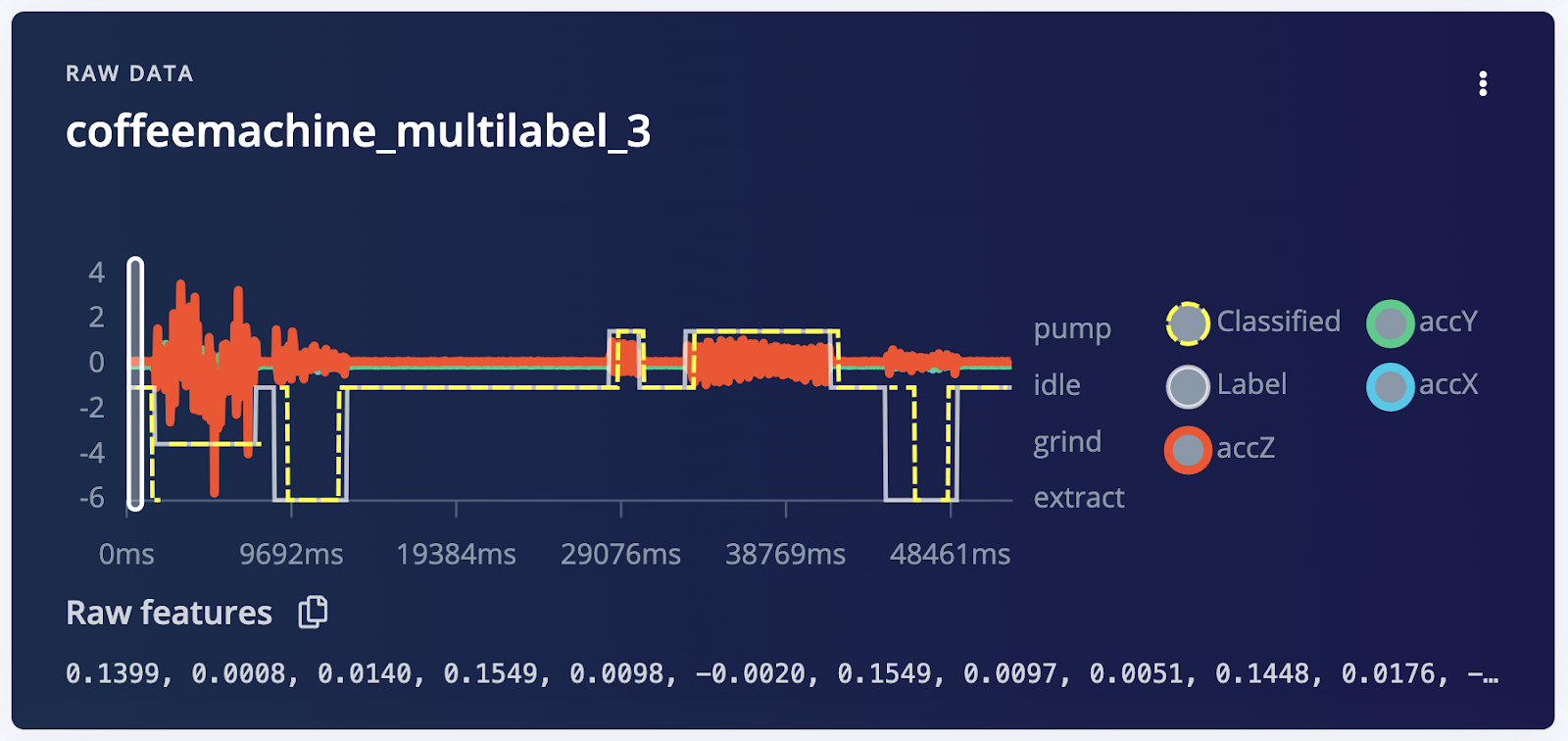
Another advantage is the direct selection of window sizes in your Edge Impulse project, which addresses the common issue of data duplication. Previously, you had to preprocess data to determine the optimal window size, a process that was time-consuming and prone to errors. With multi-label samples, adjusting the window size is now just a simple parameter change in your project, saving time and reducing errors.
More New Features Coming Soon
Looking ahead, we are working on introducing stateful Digital Signal Processing (DSP) blocks, which will further leverage the advantages of multi-label samples. These stateful DSP blocks are designed for dynamic adaptive filters and algorithms that require an understanding of prior data states, such as calculating a running mean. They will also play a crucial role in developing more sophisticated and context-aware machine-learning models.
We invite you to try out this new feature and see the difference it makes in your data analysis processes. As always, we value your feedback and suggestions, which play a critical role in the ongoing improvement and development of our features. For more information, guidance, and examples, feel free to explore our dedicated documentation page.