This guest post comes from our friends at Dojo Five. With over 335+ years of combined expertise, Dojo Five helps companies optimize their embedded software development systems by bringing together tools, techniques, technologies, and culture to deliver modern firmware for embedded systems. Dojo Five’s experience with device technology includes: IEC 62304, ISO 13485, and IEC 60601 compliance requirements and they have expertise with Class I, Class II, and Class III medical devices.
In this blog we will talk about the development considerations for a medical device that has integrated machine learning (ML) into the design. We will discuss the testing requirements for medical devices, which vary based on their classification and intended use. Biocompatibility, electrical safety, performance, software validation, and usability testing are some common types of testing required for FDA approval of medical devices. When developing a medical device with ML, it is critical to clearly define specifications, including the algorithms used for data processing, data sources, and data limitations. It is also important to set up and maintain a consistent build environment for embedded firmware, and to develop code with testing in mind from the start, including testing automation.
We cannot stress enough the importance of validation and establishment of guardrails in the embedded firmware when integrating ML into a medical device. Training data must be representative of the intended patient population and account for potential biases in the data. Validation must be rigorous and may require the use of independent datasets to demonstrate the device’s generalizability. The documentation of device specifications is also critical for the regulatory submission process. The FDA requires detailed documentation of the device’s intended use, performance characteristics, and operating conditions as part of the premarket approval process. The FDA has published some guiding principles for medical devices with machine learning.
First let’s talk about the device classifications and testing requirements for those who are not familiar with them.
Device classifications and testing requirements
The testing required for FDA approval of a medical device depends on the classification of the device and its intended use. The FDA uses a risk-based classification system to determine the regulatory pathway for medical devices. The three classifications are Class I, Class II, and Class III, with Class I being the lowest risk and Class III being the highest risk.
General testing requirements for each class of medical devices
Class I: These devices are considered low risk and are subject to general controls, such as establishment registration and product listing, quality system regulation, and labeling requirements. Most Class I devices are exempt from premarket notification requirements, but some are subject to special controls, such as performance standards or post-market surveillance.
Class II: These devices are considered moderate risk and are subject to general controls and special controls. Special controls may include performance standards, guidelines, and testing requirements. Most Class II devices require premarket notification, also known as 510(k) clearance, which requires the submission of data to demonstrate the safety and effectiveness of the device.
Class III: These devices are considered high risk and are subject to general controls, special controls, and premarket approval (PMA) requirements. PMAs require extensive testing and data to demonstrate the safety and effectiveness of the device, including preclinical testing, clinical trials, and post-market surveillance.
Common types of testing required for FDA approval of medical devices
- Biocompatibility testing: This type of testing assesses the biological response of the device to living tissue, to ensure that the device is safe for use in contact with or inside the human body.
- Electrical safety and electromagnetic compatibility testing: This type of testing evaluates the device’s electrical safety and its ability to operate safely in the presence of other electrical equipment.
- Performance testing: This type of testing evaluates the device’s performance and accuracy, including its ability to measure or detect the intended parameter or condition.
- Software validation and verification testing: This type of testing evaluates the safety and effectiveness of the device’s software, including its ability to perform as intended and produce accurate and reliable results.
- Usability testing: This type of testing evaluates the device’s usability, including its ease of use, user interface, and user experience.
Now let’s hit on the design and development considerations.
Specific design and development considerations
1. Clearly define specifications including usage of ML in the product
Clearly defining device specifications is critical for the development and regulatory approval of a medical device that includes the usage of machine learning (ML). Device specifications describe the device’s intended use, performance characteristics, and operating conditions, and are essential for ensuring that the device meets the required safety and effectiveness standards.
When ML is integrated into a medical device, it is important to clearly define the algorithms used for data processing, data sources, and data limitations. The device’s intended use must be clearly described, including its indications, contraindications, and warnings. Additionally, the device’s performance characteristics should be quantitatively defined, such as its sensitivity, specificity, and predictive values, and validated through testing.
It is important to consider how the ML algorithm will be trained and validated, since these processes can significantly impact the device’s performance. Training data must be representative of the intended patient population and account for potential biases in the data. Validation must be rigorous and may require the use of independent datasets to demonstrate the device’s generalizability.
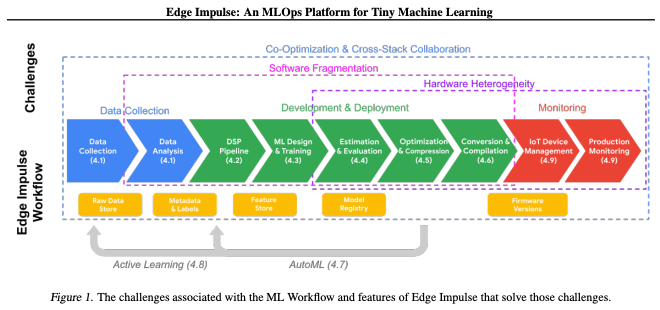
Edge Impulse reminds users that a team should strive for the highest quality data they can collect; gaps in data, or inconsistent data capture will result in nonoptimal models. This is one aspect they have tried to control with their tools. As is noted in Edge Impulse: An MLOps Platform for Tiny Machine Learning (S. Hymel et. al, 2022), “Since every ML project begins with data that is often hard to gather easily, Edge Impulse provides a number of features designed to help users collect data, manage their dataset.”
"Edge Impulse prioritizes a data-centric approach because data collection and analysis has been historically slowed down in the ML pipeline. Given the scarcity of sensor datasets in the embedded ecosystem (Challenge #1, Section 1), Edge Impulse enables users to ingest data from various sources. Therefore, Edge Impulse encourages a data-centric approach to ML development, rather than (over) emphasizing a model-centric approach."
As stressed earlier, the medical device industry has specifications on data accuracy. Ensuring quality not only relies on our dataset being representative but it must also be relevant to the domain, balanced to the desired train and test specifications (e.g. 80:20 Train:Test split), well-formatted, well-documented, and appropriately sized for the given requirements.
Once we have collected our Dataset we can begin to take steps to improve the quality. This methodology is referred to as “Data-Centric Machine Learning”, and can be a dedicated ML task or role performed by a Data Engineer. Steps can be taken by a Data Engineer or user of Edge Impulse to fix or remove mislabeled samples, removing outliers, augmenting our samples and resampling data to improve balance.
To learn more about building quality datasets for edge AI use cases, please see the How to Build a Dataset section of: “AI at the Edge,” a new publication by by Edge Impulse’s Daniel Situnayake (Head of ML) and Jenny Plunkett (Senior Developer Relations Engineer), you can register for free sample chapters of their book here.
Furthermore, the documentation of device specifications is an important component of the regulatory submission process. The FDA requires detailed documentation of the device’s intended use, performance characteristics, and operating conditions as part of the premarket approval process. This documentation must clearly describe the ML algorithms used in the device and the data sources, training, and validation processes used to develop and validate the device’s performance.
2. Set up and maintain a consistent build environment
Docker images can be an effective tool for maintaining a consistent build environment for embedded firmware, including those that incorporate machine learning (ML) algorithms. Embedded firmware development can be complex, involving multiple components and dependencies that must be configured and managed correctly to ensure the firmware is built correctly and consistently. When ML is integrated into the firmware, the complexity can increase, making it even more critical to maintain a consistent build environment.
Docker is a containerization platform that enables developers to create lightweight, portable, and self-contained environments for building and running applications. A Docker image is a lightweight, standalone, and executable package that includes everything needed to run the application, including the application code, runtime, system tools, and libraries. Docker images can be used to ensure that the build environment for embedded firmware remains consistent across different development environments, such as different computers or operating systems.
When using Docker images for embedded firmware development, a developer creates a Docker image that includes all the tools, libraries, and dependencies needed for the firmware build. This image can then be shared with other developers, ensuring that everyone is using the same build environment. This approach helps to avoid inconsistencies or compatibility issues that can arise when different developers use different tools or libraries. (Read more.)
For ML-based embedded firmware, Docker images can be particularly helpful for managing the dependencies required for the ML model.
For users that wish to include edge impulse in their Docker development environment they can simply include their Python SDK as they would any other dependency by adding the following to their image: “RUN pip install edgeimpulse”. Typically when one is working on a project collaboratively it is best practice to pin (lock) to the latest supported version for all dependencies to ensure predictable results on deployment.
Edge Impulse notes that it removes the need for developers and ML practitioners to have extensive knowledge in multiple domains, such as Python, machine learning, TensorFlow, C/C++, and embedded systems. “Although we do cater for advanced usage to enable ML practitioners, domain experts, and embedded engineers to work collaboratively with their teams and integrate into their ML pipelines through our APIs,
we also handle the heterogeneity of deployment to embedded architectures and development frameworks, and our MLOps platform is designed specifically to help scale deployment effectively.” (arXiv:2212.03332 [cs.DC])
“Not only do we enable our users to build the model architecture, build custom digital signal processing, we can also reduce the size of the deployment through optimization for the given deployment architecture, E.g. INT8 for MCUs or further reduce through our additional compilation step with our EON compiler. We can deploy as prebuilt firmware which includes drivers for the individual sensors or as a Library to your choice of supported platform.
Dojo Five has experience setting up these environments for medical devices and tools and have helped our medical device customers improve the reliability, quality, and consistency of their embedded development projects. Contact Dojo Five if you have questions or need assistance.
3. Develop code with testing in mind from the start including automation
Developing embedded firmware with integrated machine learning (ML) with testing in mind from the start is crucial to ensure that the firmware meets the required performance, safety, and quality standards. Testing can help identify bugs, issues, and vulnerabilities in the firmware, including the ML algorithms, before it is deployed in the field. (More on testing.)
There are several best practices that developers can follow to develop embedded firmware with integrated ML with testing in mind from the start. Here are a few:
- Define clear requirements: It is important to define clear requirements for the firmware, including the performance, safety, and quality requirements, as well as the requirements for the ML algorithm. These requirements can help guide the testing efforts and ensure that the firmware meets the required standards.
- Plan for testing early: Developers should plan for testing early in the development process. This means designing the firmware and the ML algorithm with testing in mind, including developing test cases, designing test infrastructure, and integrating testing into the development process.
- Implement automated testing: Automated testing can help ensure that the firmware and the ML algorithm meet the required standards consistently. Developers can use automated testing frameworks to test the firmware and the ML algorithm automatically, including unit testing, integration testing, regression testing and Hardware in the Loop testing.
- Use simulation and emulation: Simulation and emulation can help developers test the firmware and the ML algorithm in a controlled environment before deploying them in the field. This can help identify potential issues and vulnerabilities and help developers fine-tune the firmware and the ML algorithm.
- Conduct validation and verification: Validation and verification are essential steps in the testing process for medical devices with embedded ML. Validation involves ensuring that the firmware meets the intended use, while verification involves confirming that the firmware meets the performance, safety, and quality requirements.
Developing embedded firmware with integrated ML with testing in mind from the start is crucial to ensure that the firmware meets the required standards. By defining clear requirements, planning for testing early, implementing automated testing, using simulation and emulation, and conducting validation and verification, developers can ensure that the firmware and the ML algorithm are tested thoroughly and meet the required standards. These are functions that Edge Impulse can also assist with, through its platform and with its support team.
4. Guardrails around ML output
Medical device embedded software is a critical component of many modern medical devices, including those that incorporate machine learning (ML) algorithms. The embedded software is responsible for controlling the device’s operations, processing data, and generating outputs. In the context of ML, the embedded software serves as the platform for deploying the ML algorithm and applying it to incoming data.
However, ML algorithms can be highly complex and unpredictable, and their outcomes can be difficult to interpret or explain. This can be a significant challenge for medical devices, where safety and reliability are of paramount importance. To mitigate this risk, it is important to use the embedded software to put guardrails on the models generated by ML.
Guardrails are designed to limit the actions or outputs of a system to a predefined set of parameters. In the context of medical device embedded software, guardrails can be used to ensure that the outputs generated by the ML algorithm are within the expected range of values and comply with regulatory requirements.
For example, guardrails can be used to ensure that the ML algorithm is only applied to data that is within the expected range of values for the intended use of the device. Additionally, guardrails can be used to prevent the device from generating outputs that are outside of the acceptable range of values.
The embedded software needs to be designed to incorporate these guardrails and to provide feedback to the user if an output is generated that falls outside of the expected range. The embedded software can also be designed to provide data on the performance of the ML algorithm, including its sensitivity, specificity, and predictive values, as well as any limitations or uncertainties in the data.
Testing guardrails on medical device firmware is essential to ensure patient safety. Guardrails are implemented in medical devices to prevent unsafe conditions or operations that could potentially harm patients. These guardrails act as safety mechanisms that monitor the device’s performance and intervene when necessary to ensure that it is functioning within safe limits. However, as firmware is updated or changed, the guardrails can become ineffective or may not function as intended. Testing guardrails on medical device firmware helps to identify any potential issues with the safety mechanisms and ensure that they are operating correctly. This testing process is critical to ensuring that medical devices meet the highest safety standards and provide patients with the best possible care.
5. Documentation
The documentation required for FDA approval of a medical device with or without machine learning (ML) depends on the classification of the device and the regulatory pathway chosen for approval. The FDA uses a risk-based classification system to determine the regulatory pathway for medical devices. The three classifications are Class I, Class II, and Class III, with Class I being the lowest risk and Class III being the highest risk. (More on device documentation.)
Common types of documentation required for FDA approval of medical devices
The documentation required for FDA approval of a medical device depends on the classification of the device and the regulatory pathway chosen for approval. Common types of documentation include premarket notification or approval submissions, quality system documentation, design control documentation, clinical study reports, and labeling and instructions for use. Medical device manufacturers must carefully follow the FDA’s requirements for documentation to ensure the safety and effectiveness of the device for its intended use. Some common types of documentation may include:
- Premarket Notification (510(k)): For Class II devices, the FDA requires a premarket notification submission, commonly referred to as a 510(k). This submission includes documentation demonstrating that the device is substantially equivalent to a legally marketed device or a predicate device. The 510(k) submission must include a detailed description of the device, labeling, indications for use, and a summary of testing and validation results.
- Premarket Approval (PMA): For Class III devices, the FDA requires a premarket approval (PMA) application, which is a more comprehensive submission than a 510(k). The PMA submission must include data demonstrating the safety and effectiveness of the device, including results of preclinical testing, clinical trial data, and labeling information.
- Quality System Documentation: All medical devices, regardless of classification, are subject to quality system regulation requirements. This documentation includes a quality system manual, standard operating procedures (SOPs), work instructions, and records of training, internal audits, and corrective and preventive actions.
- Design Control Documentation: Medical device manufacturers are required to follow a design control process that includes documentation of design inputs, design outputs, design verification, design validation, and design transfer.
- Software Lifecycle Documentation: Defined by the IEC62304 standard, is a set of documents that describe the processes, activities, and artifacts involved in the development of medical device software. This documentation is intended to ensure that software development processes are conducted in a systematic and controlled manner, and that the resulting software is safe, reliable, and effective for its intended use. The software lifecycle documentation includes various documents such as the software development plan, software requirements specification, software architecture specification, software design specification, software verification and validation plan, software risk management plan, and software configuration management plan. These documents provide a framework for the development, testing, and maintenance of medical device software throughout its lifecycle.
- Clinical Study Reports: For devices that require clinical trials, the FDA requires documentation of the clinical study, including the study protocol, informed consent forms, and study data.
- Labeling and Instructions for Use: The FDA requires labeling and instructions for use for all medical devices. This documentation includes instructions for use, warnings, precautions, and contraindications.
In conclusion, the integration of machine learning (ML) into medical devices requires special attention to testing, regulatory compliance, and the specific considerations related to ML development. The development of a medical device using ML requires the clear definition of the device’s specifications, including the algorithms used for data processing, data sources, and data limitations. Testing requirements are determined by the device’s classification and intended use, with biocompatibility, electrical safety, performance, software validation, and usability testing being the most common. It is also important to establish a consistent build environment and develop code with testing in mind from the start, including automation.
In addition, the development of medical devices with ML requires a rigorous validation process, training data representative of the intended patient population, and the documentation of the device’s specifications, ML algorithms used, and the data sources, training, and validation processes used to develop and validate the device’s performance.
Dojo Five has helped our medical device customers improve the reliability, quality, and consistency of their embedded development projects. Learn more about our modern tools, techniques, and best practices for your embedded medical device development projects.