
One of the great things about artificial intelligence (AI) is its remarkable ability to recognize complex spatial and temporal patterns in data that might otherwise elude us. It is also exceptionally well-suited to automating the process of collecting the raw data from which such patterns can be derived. This, in turn, slashes the time and costs associated with labor-intensive manual work, which would otherwise be necessary. But once we get the results from a system of this sort, the large volume of data can be enough to make our heads spin. Sometimes the explanations need an explanation.
Machine learning enthusiast Jallson Suryo was recently considering this issue in the context of building visitor behavior analysis. When performing these analyses, one wants to understand the typical behaviors and traffic patterns of people visiting restaurants, shops, office spaces, and other public places. This is important because it can help building managers to arrange for a more efficient flow of foot traffic and better utilization of climate control and lighting resources. However, tracking all of the visitors in a busy public space over the course of time produces a lot of data that is hard to interpret, even with an AI-powered boost.

A common method for collecting this data involves the use of a computer vision algorithm that recognizes people, then tracks their positions over time. But many thousands of images with dense clusters of overlapping bounding boxes identifying detected people is exceedingly difficult to translate into trends over time. Suryo realized that the data itself is exactly what is needed to solve this problem — it is just how we visualize it that is the problem. To address this issue and demonstrate a better path forward, he built a prototype system that tracks building visitors with Edge Impulse’s FOMO object detection algorithm, then uses that data to build a heat map that can reveal temporal trends at a glance.
To make this system practical for use even by small businesses, Suryo chose to work with the inexpensive NVIDIA Jetson Orin Nano Developer Kit. Don’t let the low cost fool you — this little computer is powerful enough for even very demanding computer vision workloads. The onboard NVIDIA Ampere architecture GPU with 1,024 CUDA cores and 32 tensor cores makes it capable of performing up to 67 trillion operations per second. And with power consumption of as little as 7 watts, you don’t have to feel bad about keeping it up and running around the clock to analyze visitor data. The only other hardware component needed for the build was a basic USB webcam.
As previously mentioned, Suryo had decided to use Edge Impulse’s FOMO object detection algorithm. It is highly optimized for edge computing platforms, so it will have no problem at all running on the Jetson Orin Nano. But before I get ahead of myself, the FOMO model first needs to be trained, and that process begins with collecting training data.
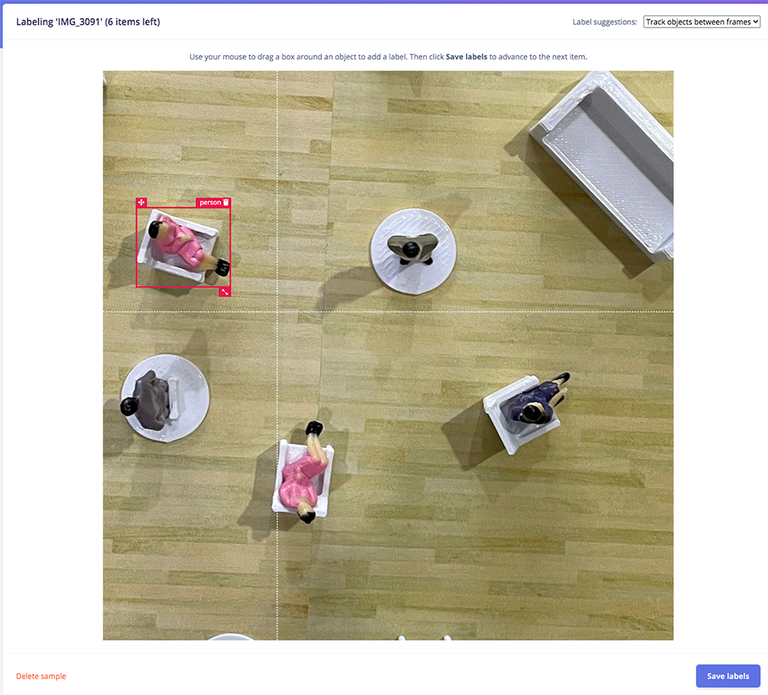
To simplify data collection during the development phase, Suryo set up a miniature model of a restaurant, complete with miniature figures. The webcam was then positioned above this faux restaurant using a structure made from aluminum extrusions. After that, Suryo did his best to relive his days as a child playing with action figures. By moving the tiny people all around the set, he was able to simulate foot traffic while the camera snapped pictures.
Next, the captured images were uploaded to an Edge Impulse project using the Data Acquisition tool, which automatically split them into training and test sets. For use with an object detection model the images also needed labels — that is, bounding boxes that identify the objects of interest. These labels were added with the help of the Labeling Queue tool, which fortunately offers a number of AI-powered options to assist in drawing the boxes. Without some assistance, drawing the boxes for even a few hundred or thousand images can be very tedious.
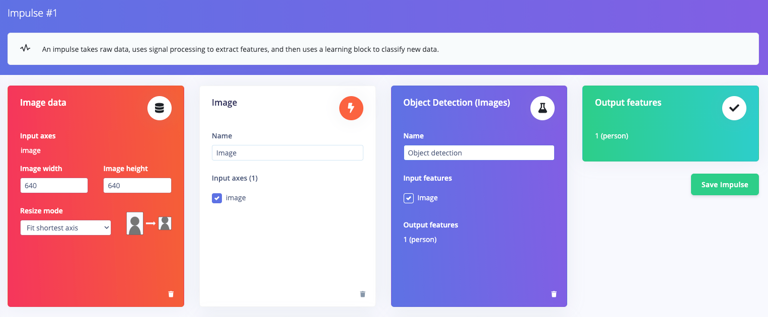
With labeled data ready to go, Suryo was ready to build the impulse. The impulse defines exactly how data will be processed, from the time an image is captured until all the people in the image are identified by the algorithm. This began with a preprocessing step that reduced the resolution of the images and converted them to grayscale, since people can be recognized just fine under these conditions. This was done to reduce the downstream computing resources that are required by the model. Next, a FOMO model was added to the impulse for person detection.
After tweaking a few model hyperparameters, the training process was kicked off. A short time later, it was reported that the model had achieved an average accuracy level of 95.5%. This result was confirmed by the Model Testing tool, which validates the model’s performance using a set of data that was not included in the training process.
Things were looking quite good, so all that was left to do was deploy the model to the Jetson. This was accomplished by downloading the impulse as a TensorRT library, then using the Edge Impulse SDK to start it up on the Jetson. Initial testing showed that the system was identifying the miniature figures with a high level of accuracy, and with incredibly fast inference times of just 3 to 5 milliseconds.
Suryo was not quite done yet, however. Since he wanted to turn FOMO’s output into an easy-to-understand heat map, he developed a Python script for the job. This took in the locations of objects detected by FOMO, and their associated timestamps, to produce a heat map that represents the presence of people over time. That made it easy to see hot spots of activity, as well as unused locations, throughout the course of an entire day at one glance.
While this work was a prototype, moving the device to a real-world setting should not add many more challenges. The same hardware can be used, and after swapping out the training data with images of real people, the software should pretty much chug along as it did in the demonstrations as well. If you would like to test it out for yourself, be sure to read through the project write-up first for some more pointers and resources to help you along the way.