
We’re thrilled to announce the launch of our new public datasets within the Edge Impulse documentation. This space is designed to share a variety of datasets that highlight specific use cases, helping you get started with edge AI and understand different types of data. These datasets are not meant for building production models, but instead serve as practical examples to guide developers, researchers, and students in their exploration of edge AI applications.
Why do these datasets matter?
In machine learning, the quality of your dataset can make or break your model’s performance.
Understanding the right type of data for your application is a key part of building any machine learning model. By offering these datasets, we aim to provide a starting point for you to experiment, learn, and prototype models in a variety of real-world scenarios. Whether you're working on object detection, audio classification, or visual anomaly detection, these datasets will help you grasp the data requirements and challenges you'll face at the edge.
Example datasets
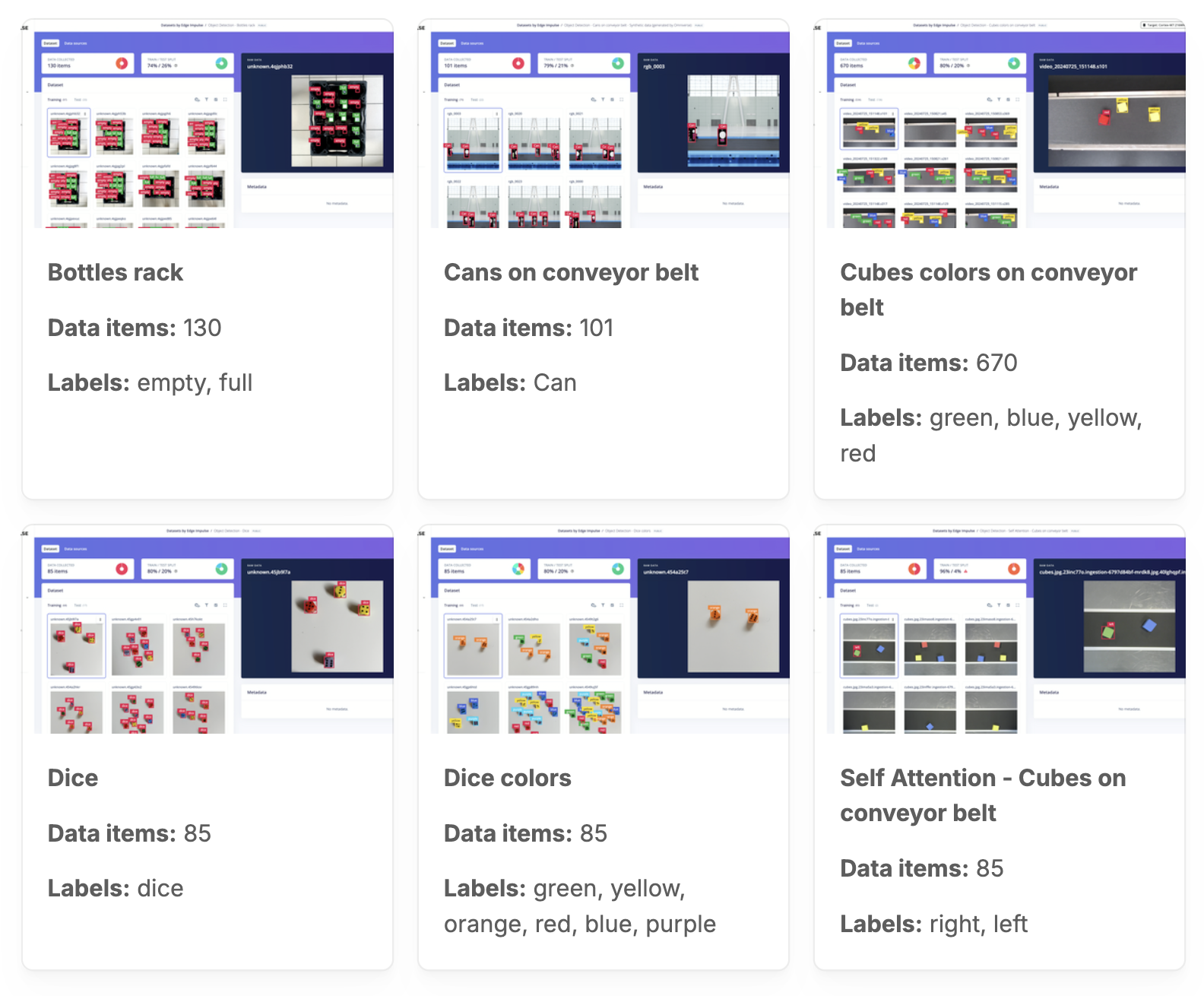
Here are a few highlights from our curated datasets:
- DHT11 (Visual Anomaly Detection): This dataset features images of a DHT11 sensor, with both nominal and anomalous samples. While the training data contains only "nominal" (no anomaly) images, the testing dataset includes examples of anomalies such as melted plastic due to overheating and missing wiring pins. It’s a great resource for learning how to apply visual anomaly detection in quality-inspection scenarios.
- Cubes on Conveyor Belt (Object Detection): This dataset was instrumental in the development of Edge Impulse’s FOMO (Faster Objects, More Objects) architecture. It contains images of colored cubes moving along a conveyor belt, labeled as green, blue, yellow, and red. This dataset demonstrates object detection for industrial automation and robotics environments, where rapid, efficient detection of multiple small objects is crucial.
- Continuous Motion Recognition (Time-series): Collected for the Continuous Motion Recognition tutorial, this dataset includes sensor data that captures various motions such as updown, snake, wave, and idle. It’s ideal for exploring motion-based applications like gesture recognition or wearable device monitoring.
A resource for learning, not production
These datasets aim to provide a diverse set of examples to help you understand different use cases and types of data encountered in edge AI projects. While not designed for production-grade models, these datasets offer valuable insights into data acquisition, labeling, and model training, helping you get familiar with the process.
Our focus is on datasets that reflect real-world use cases, from audio and motion data to visual anomaly detection. We invite you to explore these datasets, leverage them in your projects, and contribute to the growing body of edge AI knowledge.
How to get started?
Visit the new public datasets in our documentation to browse the full collection. From there, just clone the public projects associated with the dataset and start experimenting!
Whether you’re working on industrial safety, smart monitoring, or any edge AI project, these datasets are here to help you build better models faster.
What's next?
We aim to add more useful datasets over time, host them on other services such as Kaggle and Hugging Face, and, finally, we want to keep improving the current ones with more data samples and additional metadata!
If you would like to see any particular use case covered in the dataset section, let us know on our forum.