Edge Impulse is the place for developing edge AI solutions to real problems and for real products, but it also allows for anyone to discover and explore edge AI for themselves. And what better way to learn a new tech tool than with the ubiquitous “Hello World?”
There are countless “Hello Worlds;” in edge AI it is commonly considered to be making a simple cat detection project. This project is very much that, my own attempt to spot my neighbor’s orange cat and keep it from bullying my outdoor cat (in a humane and hopefully entertaining way).
Just as customer projects get feature creep, however, so do pet projects that take place over months of late nights and weekends, so I’ve broken the endeavor into three sections, the first part here and the ensuing two to follow shortly after.
Part 1: Cleaning & labeling a large cat dataset with AI actions (you are here)
Part 2: Using state-of-the-art synthetic data for a bespoke wildlife detection model (next)
Part 3: Putting it all together and combining the best of both edge AI and cloudAI (final)
Cleaning & labeling a large cat dataset with AI actions
Edge Impulse, along with all AI and ML experts, always emphasize the importance of Data Data Data and no, I’m not trying to summon our favorite cat-loving android from the united federation of planets as if he were Beetlejuice. What I am stressing is how critical it is to ensure you have a robust dataset, and just as importantly, the dataset is clean before developing a model, as image elements like borders, watermarks, text, etc. can reduce overall performance and limit your solutions when your product or design would have functioned as intended, if not even better, had your dataset been cleaned up properly in the first place.
Very specific datasets have to be built, but for general projects like this, we can find huge, pre-assembled, but not totally verified collections of images of cats on dataset repositories such as Kaggle.
The problem is, how can anyone clean a dataset of 126673 cats from Kaggle (posted by user ma7555 and taken from the Petfinder API) and remove all of the images that will negatively affect our models without resorting to tediously sorting through them one at a time? We will use the latest LLMs to do it for us!
In Edge Impulse Studio you can use our AI Labeling block for Image labeling with GPT-4o
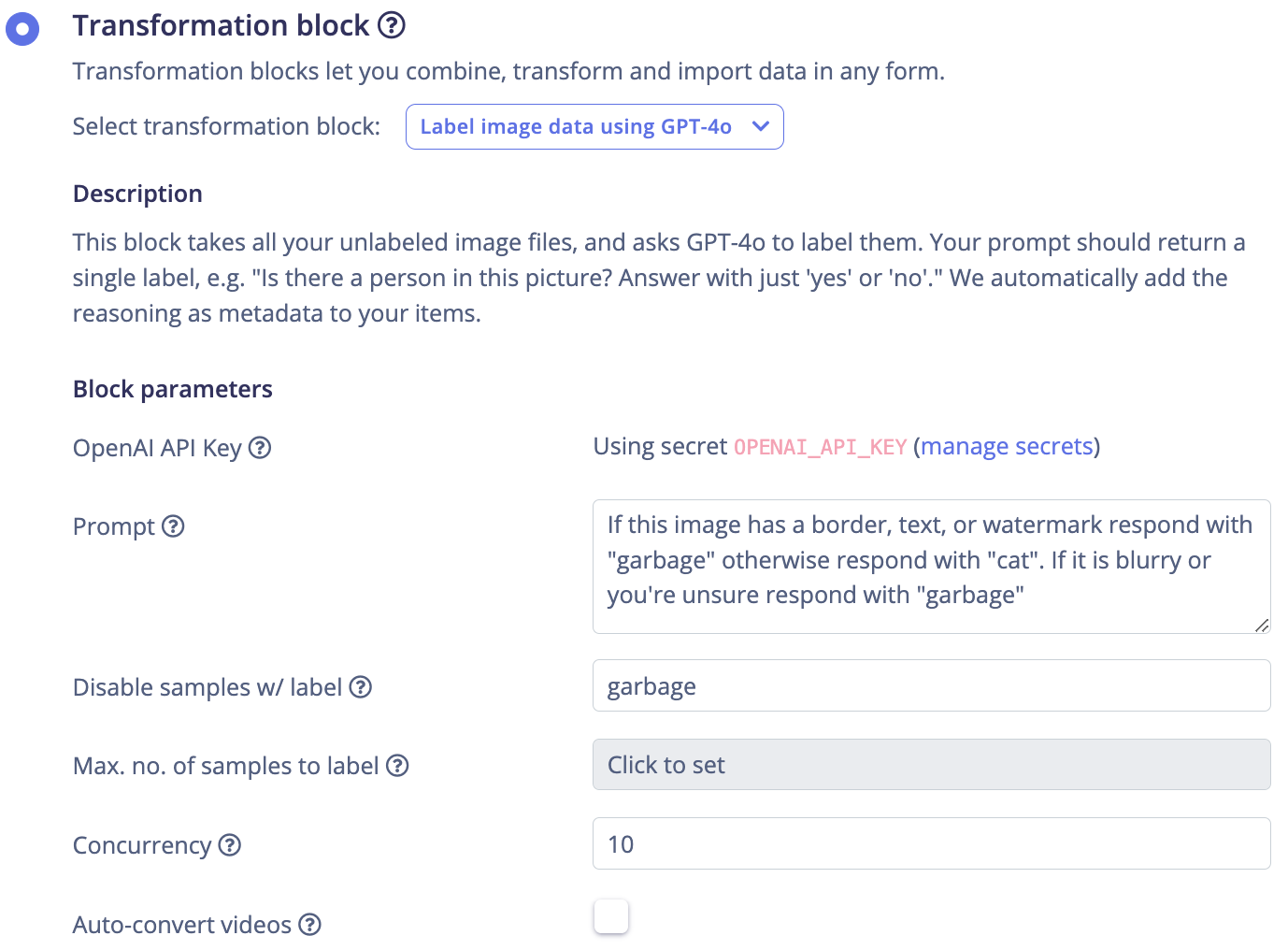
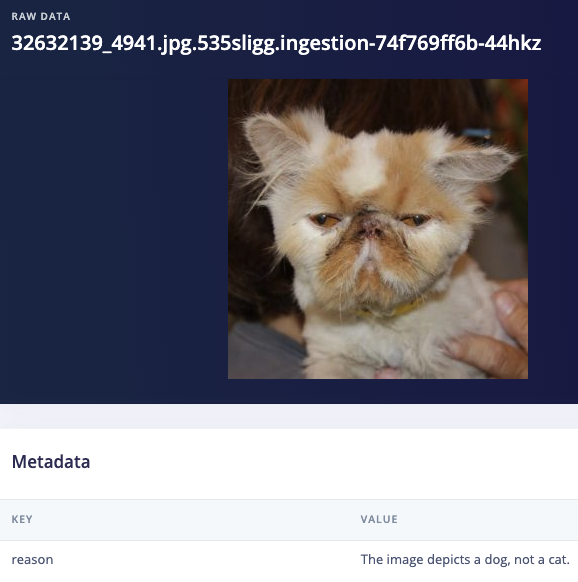
I actually decided to start with the (cleared) dataset from user denispotapov which had 118813 images, and then ran the labeling transformation block with the prompt seen above, “If this image has a border, text, or watermark respond with "garbage" otherwise respond with "cat". If it is blurry or you're unsure respond with "garbage"” which left me with 97672 images, thanks to GPT disabling 21141 images for being unusable because with edge AI the old adage applies, “Garbage in, Garbage out.”
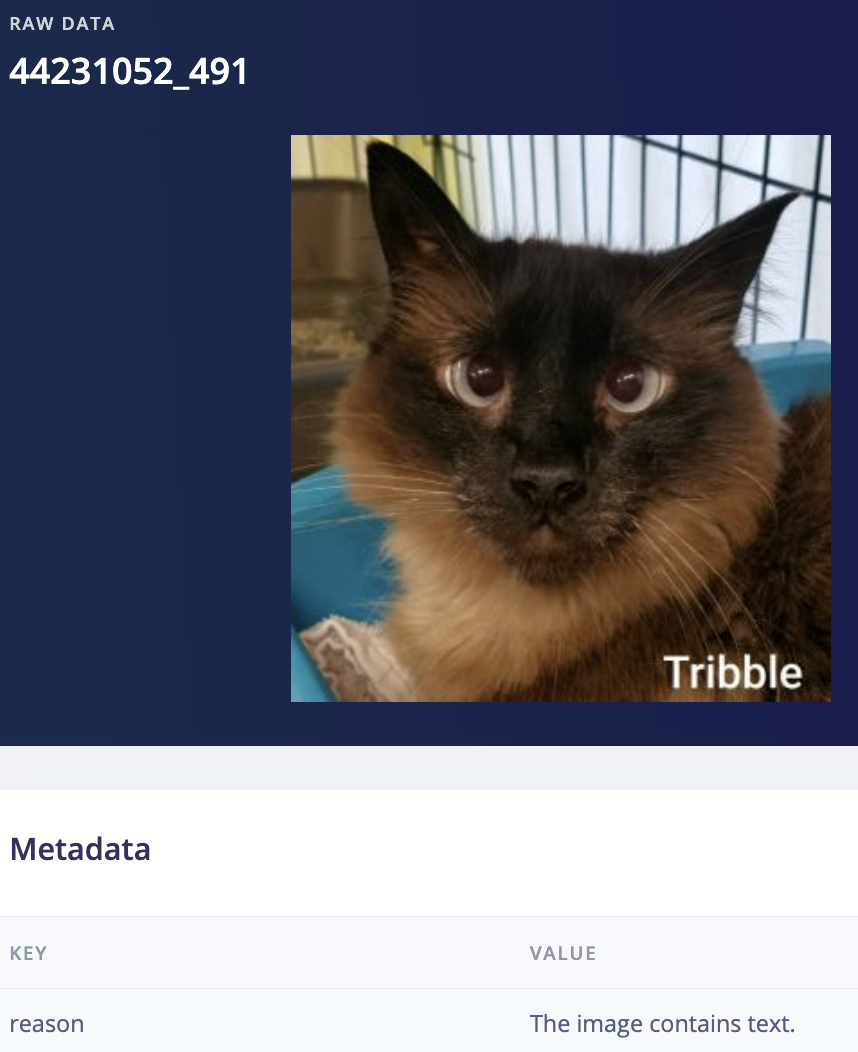

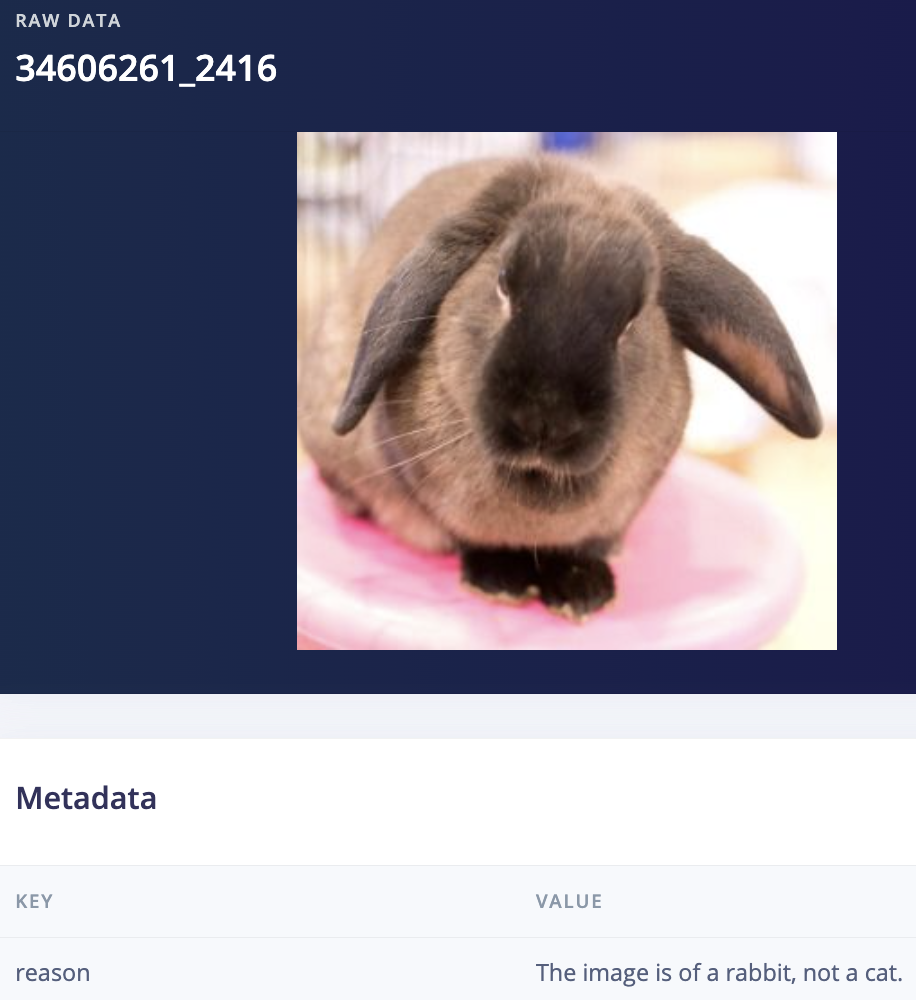
(there were 14 images of rabbits masquerading as cats)

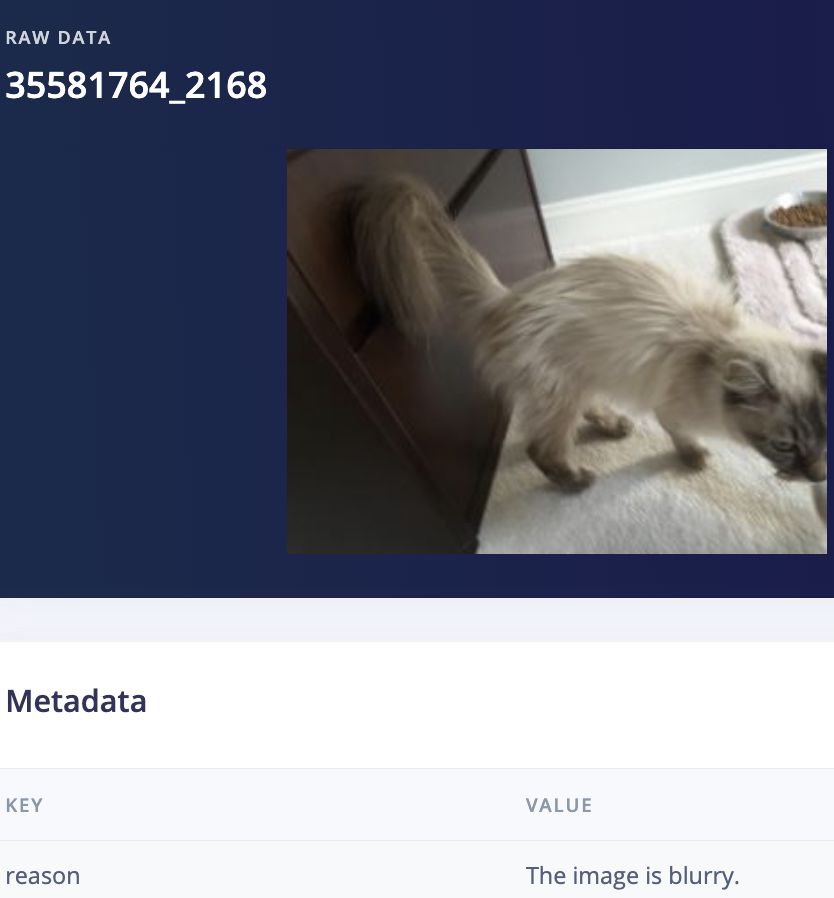
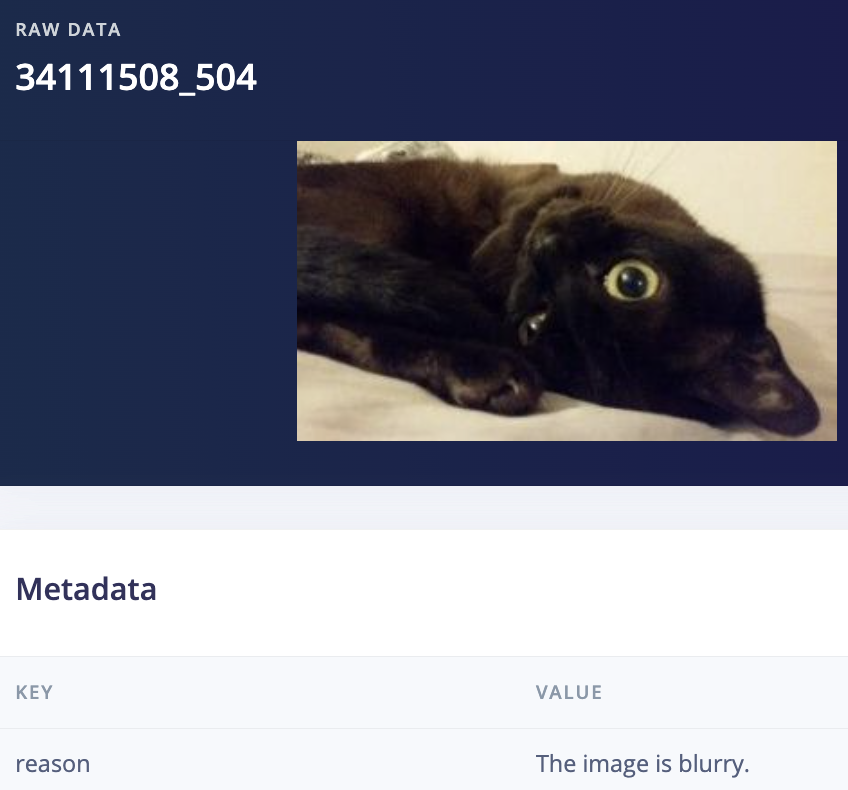
(there were 12978 blurry images)
Since my neighbor’s cat is orange and my outdoor cat is most definitely not, I also had GPT sort through the resulting dataset and classify them into orange-cat/not-orange-cat (okay the real class names were Garfield & Nermal) so that I can use it for a classifier to cascade after my cat detection model. In case you’re wondering, there were only 10194 orange cats, or 10.4% of the cleaned up dataset, but the remainder of this portion of the project will be discussed in part 3.
(Side note: all of this led to our incredibly understanding co-founder and CTO, Jan Jongboom, sending out a company-wide email on a weekend while he was on vacation revoking our OpenAI API key because someone was using it so excessively he was concerned it may have been leaked, so thanks again Jan for letting me continue to use your OpenAI credits to finish this project!)
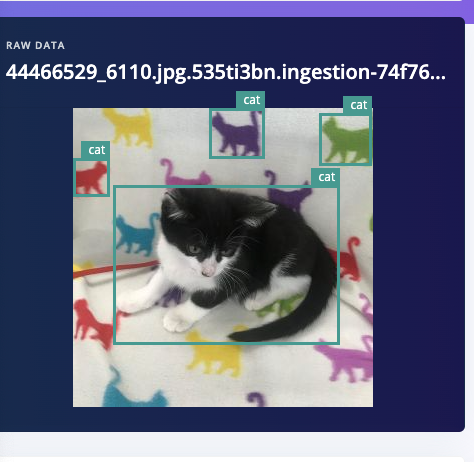
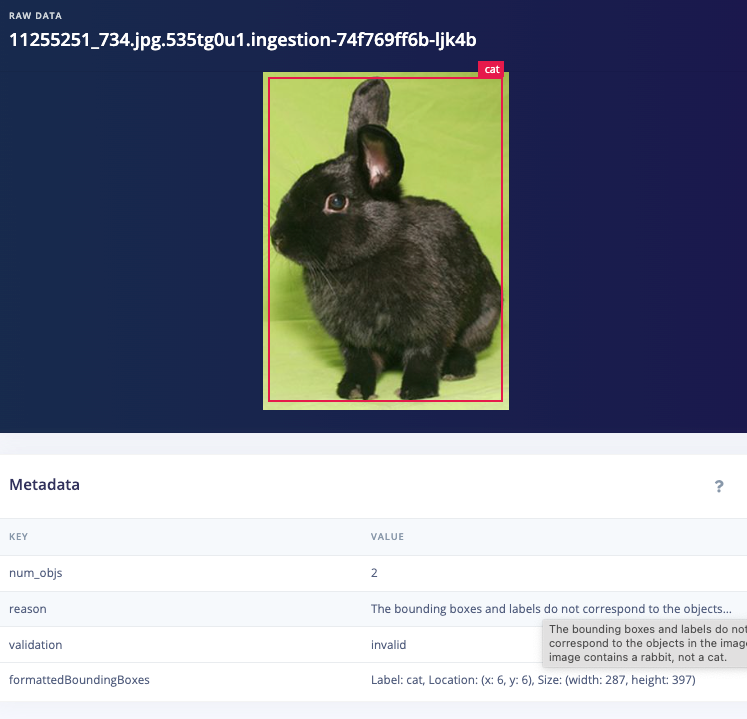
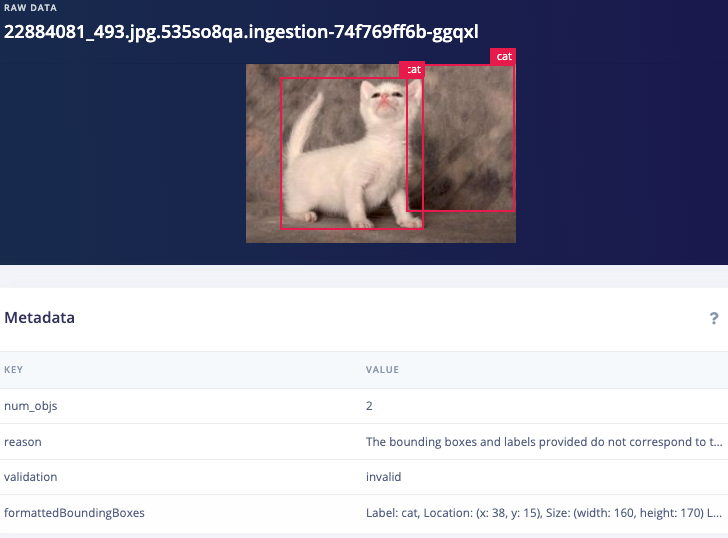
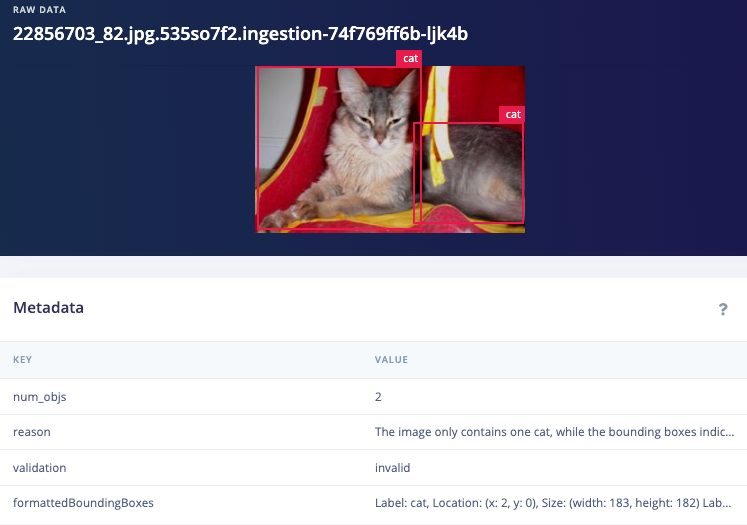
Before I use the Garfield/Nermal classifier I need an object detection model, but this dataset wasn’t labeled for object detection with bounding boxes, only cat breeds, so what do I do now? The OWL-ViT AI Labeling Block will work very well for this task, but it just wasn’t in the platform at the time when I first wrote this series, so I mashed it together in Google Colab with a little help from our brilliant ML team. First I used YOLOV8X to autolabel every image and then a quick script to remove all bounding boxes except ‘cat’, leaving me with 86139 images. But that’s still not good enough for my model because my autolabeling step could have included inaccuracies like bounding box locations, so I had GPT help out again with one final cleanup operation, this time using our bounding box validation with GPT-4o AI labeling block (thanks Jim Bruges!)
Validation1: "The bounding boxes and labels do not correspond to to the objects in the image"
Validation2: "The image is incorrectly rotated"
Validation3: "The image is not clear enough to determine the objects in the image"
Example disabled images
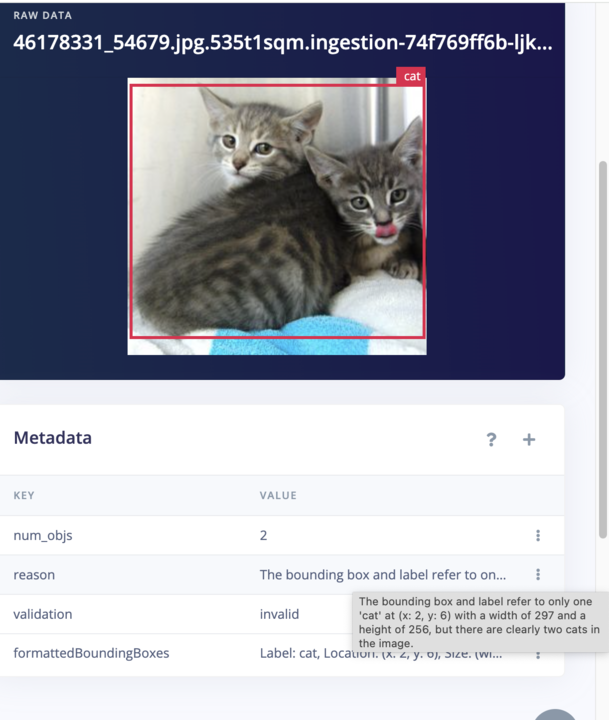
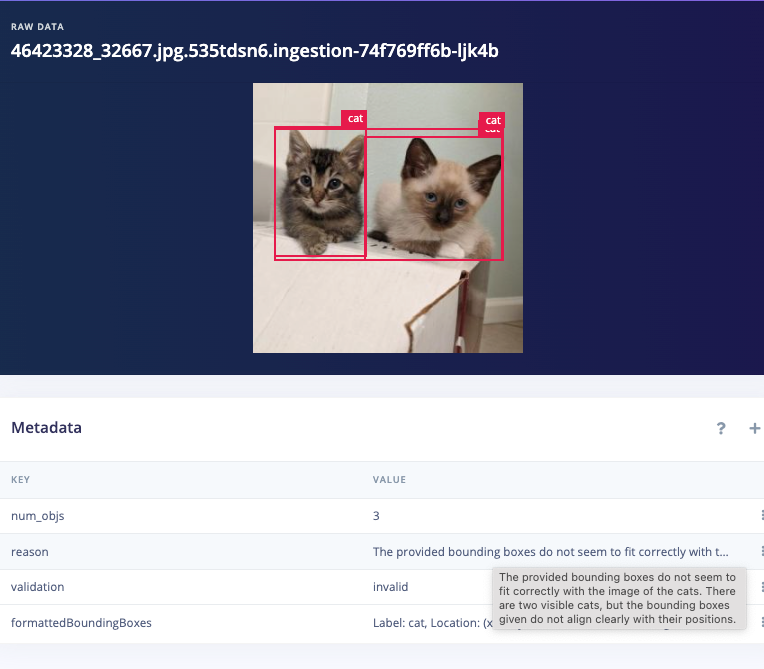
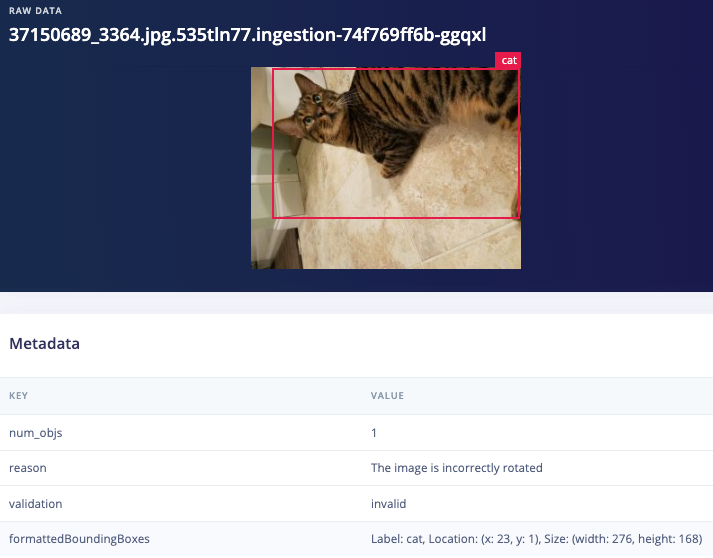
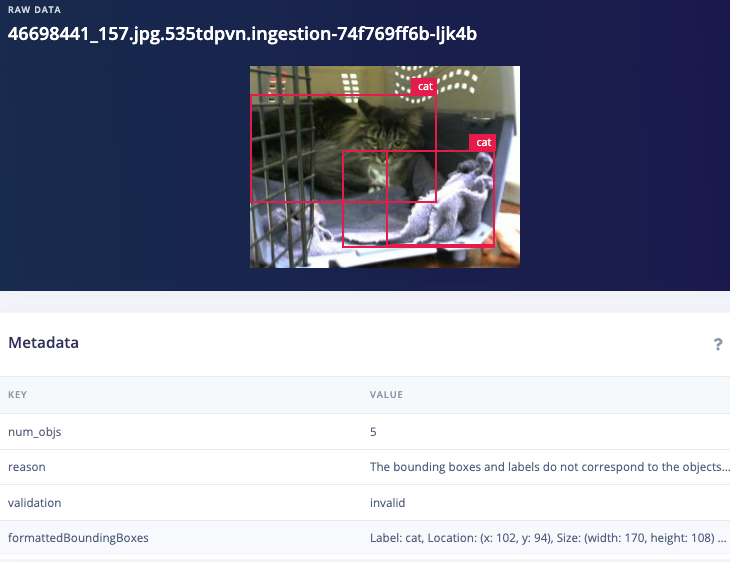
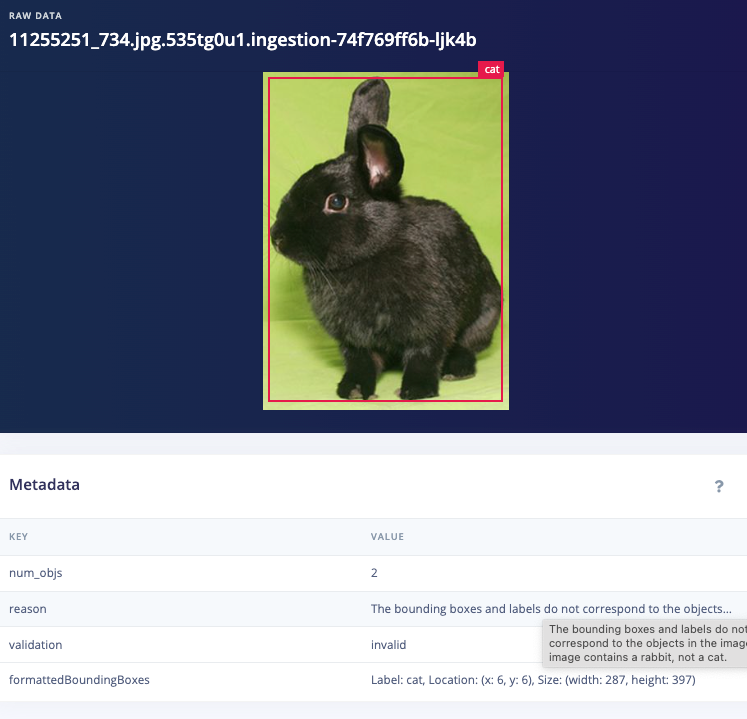
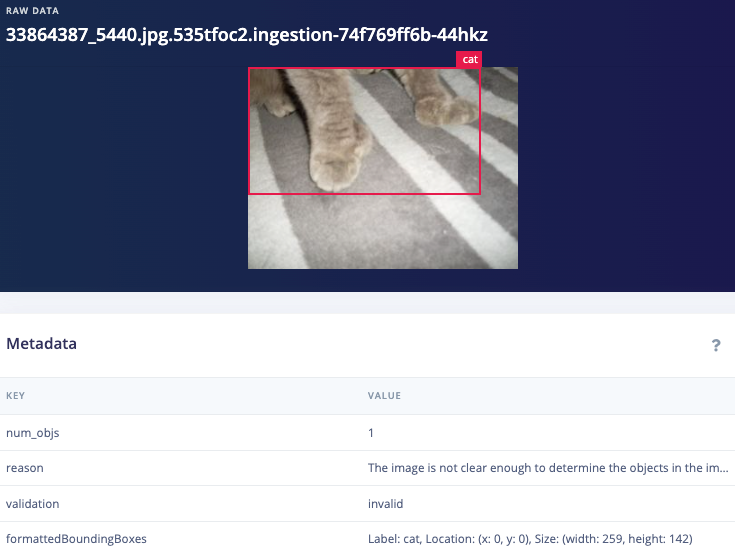
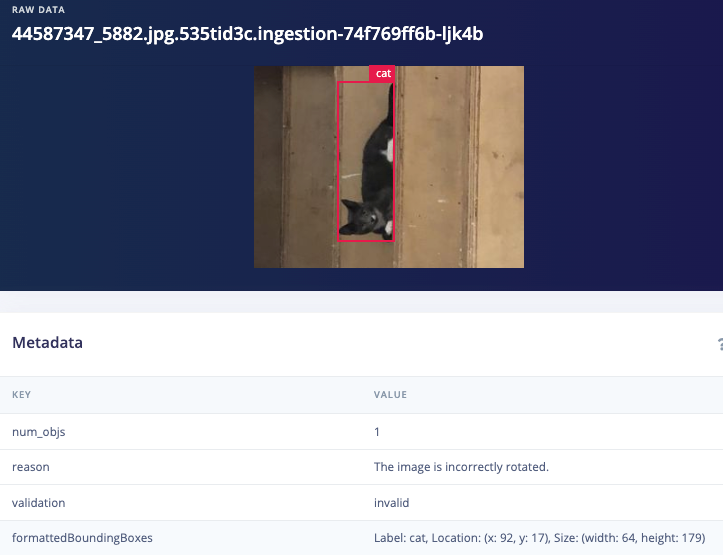
Dataset cleaning & labeling path
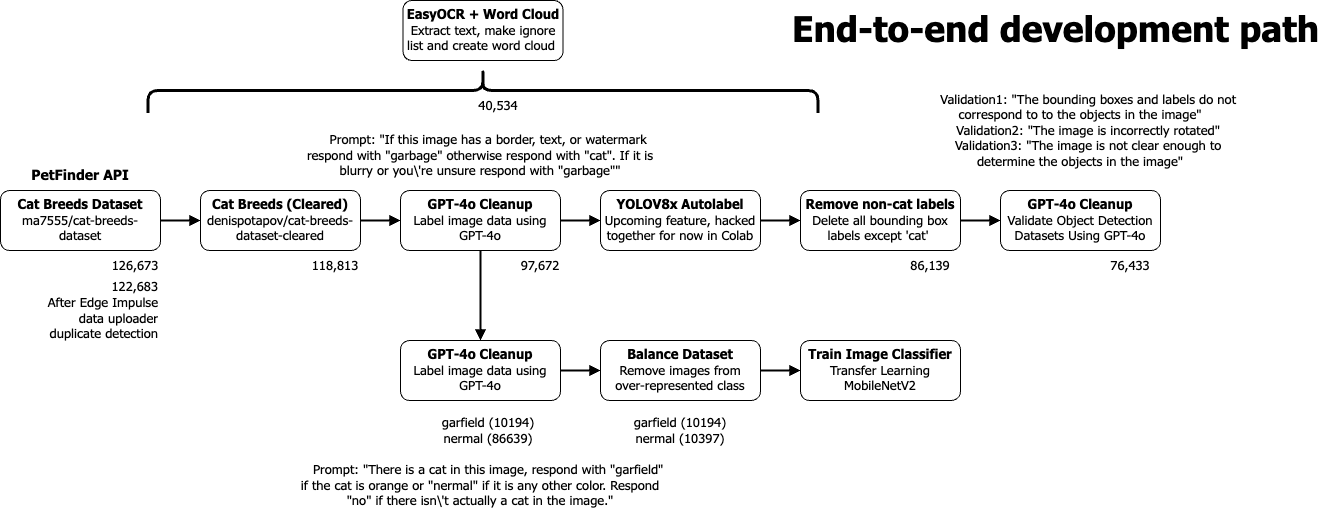
Finally we are down to as clean of an autolabeled public dataset as we can get without touching a single image ourselves: 76433 labeled cat pictures, ready to use in our object detection model experiments that will be covered in part 3. So now you’re probably asking, “then what is part 2 all about?” Well, as much as my neighbor’s cat likes to come over on weekends when his owners clean their house, my bigger problem is the raccoons that show up every few nights to raid the cat food and use the water dish as a sink for their dirty, trash-covered paws. Except there aren’t good datasets of raccoons available and the ones that are out there show raccoons in daylight — pretty useless, since they are generally nocturnal animals and appear around midnight. The only data I have is my grainy Ring footage. With Edge Impulse, however, that’s not a problem; I used the latest state-of-the-art text-to-image model from Black Forest Labs, Flux-pro, to generate thousands (yes thousands) of images of feral raccoons late at night as if taken by a security camera to provide 95% of my data for a nighttime raccoon detection model which should be robust enough.
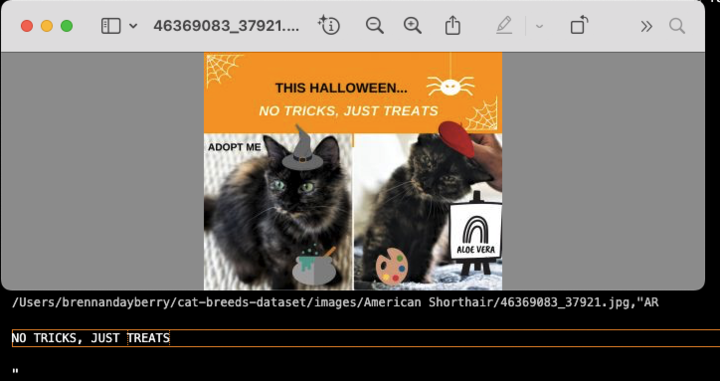
To finish this first part, I wanted to end on a positive note since I love all animals… I realized it would be neat to do a tangential project with all of the images that were removed in the first round of cleaning. As they were from Petfinder, the images with text likely had cat names, so what if I ran a quick Optical Character Recognition (OCR) tool over them and parsed out all the names to see which are the most common?
Well after a painstaking weekend of my spouse helping me to add ignore-words like “adopt” and phone numbers of shelters, I finally ended up with this lovely word cloud of the most common cat names as found in the ~40,000 images removed by cleanup and autolabeling blocks during this process.

The YOLOV8 autolabeling step also produced some interesting metadata in the number of other objects found in the dataset. For instance, the 1327 dogs are mostly just images of atypical cats, while all of the ties are because of the many adoption pictures where shelter volunteers would dress the cats up to increase their odds of finding their ‘furrever’ home.
Top 25 items found in dataset
Lastly I have to share a few “bloopers” resulting from the YOLOV8 autolabeling step that are pretty adorable for various reasons.
Stay tuned for parts 2 and 3!