
The explosion of computer vision and its integration into countless products has sparked an insatiable appetite for data. Edge Impulse simplifies the workflow of deploying these models, but collecting quality data can still be a daunting challenge — often time-consuming, and sometimes even impractical.
Luckily, synthetic data offers a promising solution to this issue, allowing users to refine their models without the limitations of traditional data collection. The technique poses many advantages: it is often faster and cheaper to gather, offers the ability to create rare scenarios, and maintains more control over private and sensitive data.
In this blog, I’ll provide you with some of my takeaways from creating my own synthetic datasets to enhance model development on the Edge Impulse platform.
Part 1: World Building in Omniverse
NVIDIA’s Omniverse is a tool that fills the gaps in constructing synthetic data. The application is essentially a virtual world-building platform that allows you to create and program a three-dimensional scene. What distinguishes Omniverse, however, is its ability to generate and collect synthetic data using its Replicator framework, which can be accessed in many of Omniverse’s built-in applications.
Coming from a brief background in computer-aided design (CAD), I found the platform to be similar to other tools I have used in the past. That being said, much like tools like AutoCAD or Unity, navigating Omniverse can initially feel overwhelming. Building your 3D world is often the most time-consuming part of the process, so I have outlined some of my tips below to make this a little more digestible:
- Use pre-built assets: Omniverse has a plethora of pre-built assets you can click and drag into your environment. It might be worth scrolling through their catalog to see if there is anything you can use in your scene. I had some experience playing around with their conveyor belt asset, which I found pretty handy.
- 3D scanning app: Something that I found particularly intriguing was Omniverse’s extension with Magi Scan. The app uses lidar to create a 3D model of an object and then can upload it into Omniverse with a QR code. It even has the ability to scan whole rooms! I do want to mention, though, that it can take several days for your model to complete rendering if you do not want to pay the premium for the app. So, it is best to be intentional about your scans.
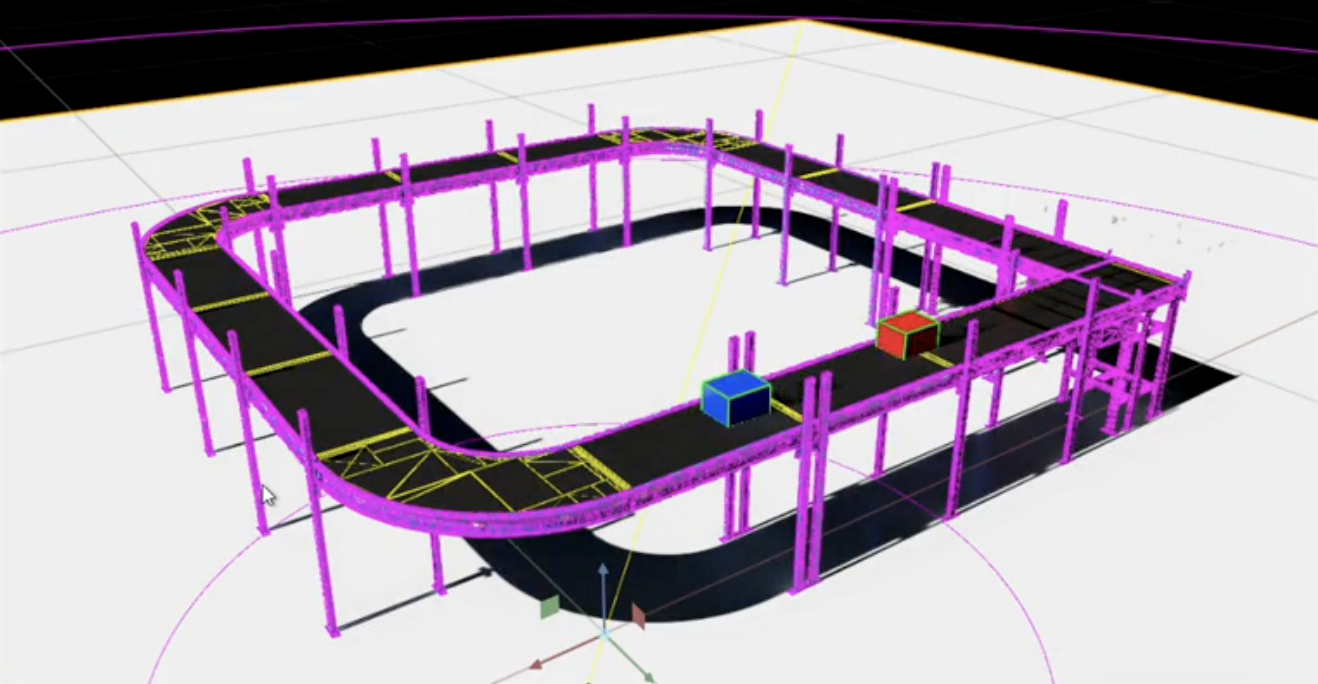
Part 2: Data Collection and Semantics
This next part will focus on my tips for using Omniverse Replicator to create your synthetic dataset. I have broken this down into some key steps:
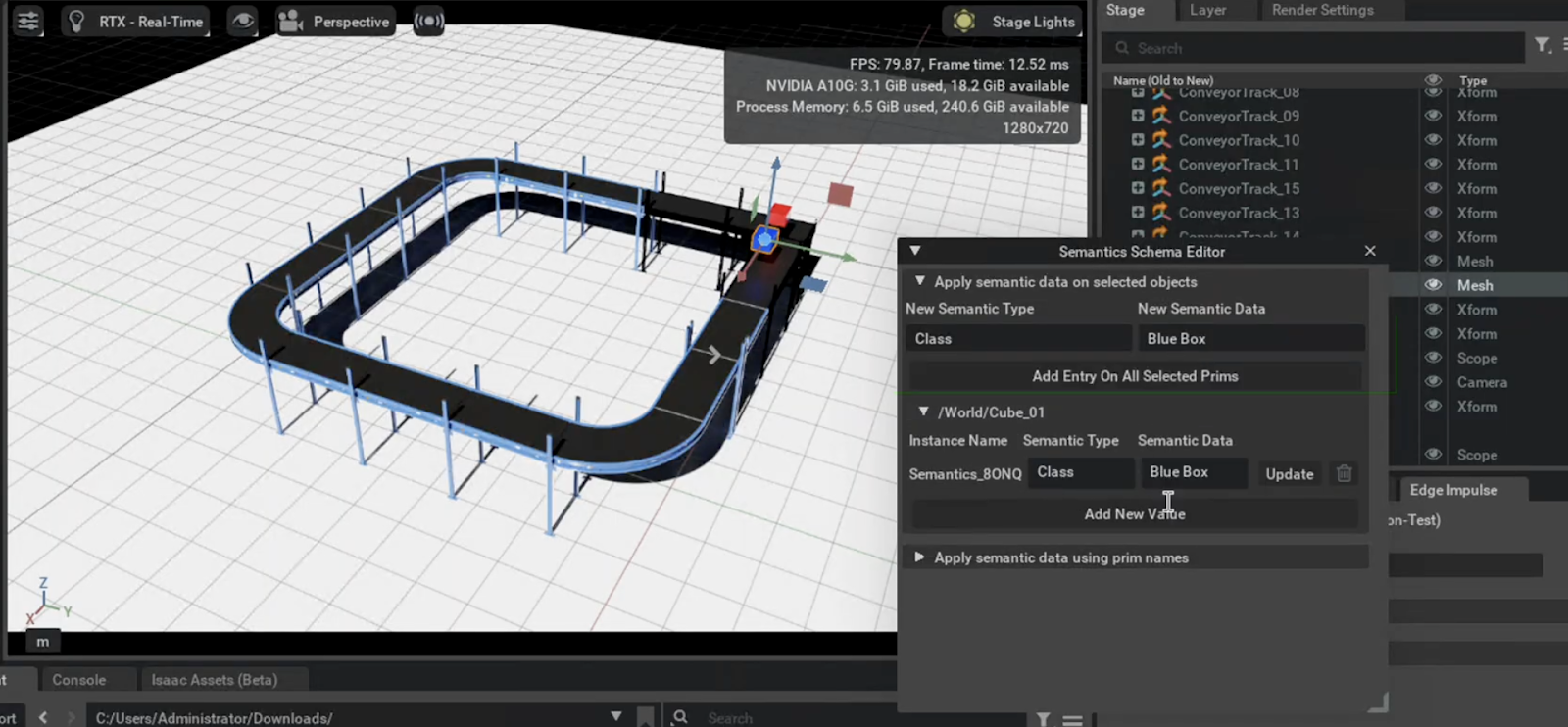
- Adding semantics (meaning) to your scene. This is necessary if you want to collect bounding box information. In order to do this, you must use the Semantic Schema Editor under Replicator -> Semantic Schema Editor. You only need to add semantics to the objects for which you would like to have bounding boxes.
- Preview your data using the Synthetic Data Visualizer found next to the camera button.
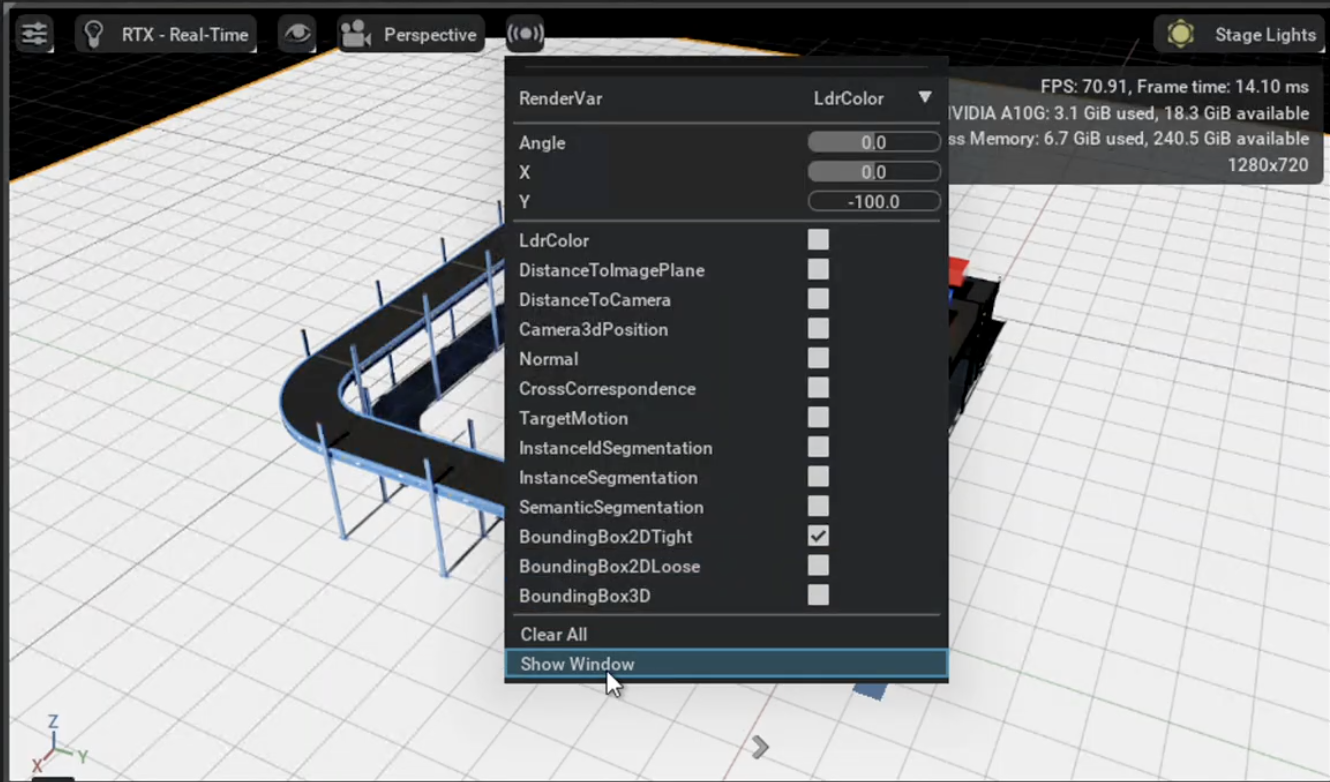
- Collect your data using the Synthetic Data Recorder under Replicator -> Synthetic Data Recorder. Make sure you check the correct parameters in the tool or else you might not collect the proper data. For example, if you want to collect images and their bounding boxes, make sure to check the 2D bounding boxes and rgb fields under the Parameters drop-down.

Part 3: Uploading to Edge Impulse
As of right now, the Edge Impulse Omniverse extension accommodates uploading images from the Omniverse Replicator output, with bounding boxes in the works. You can find the documentation for this here!
Next Steps
George Igwegbe has a great example of creating synthetic datasets using NVIDIA Omniverse Replicator, so I would point you to his article if you are curious about some real-world applications and adding variation to your dataset.
There are many implications that synthetic data can have on the future of training models. Something else to explore would be how realistic (or non-realistic) you can get in your dataset and still have good performance in the real world, and whether or not to filter synthetic features from the training process. Regardless, I hope that this blog helped demystify the process of creating synthetic datasets and lay the groundwork for some of your own exploration.