
Over the past few months, you’ve may have heard talk about TinyML: the idea of running machine learning models on microcontrollers, and other small devices that don’t use much power.
TinyML is exciting because it helps tiny devices make decisions based on huge amounts of data—without wasting time and energy transmitting it elsewhere. For example, imagine you’re tracking animal behavior in the African Savanna. You want to know how often lions roar at different times of the day.
You have a few choices of how to collect this data:
- Hideout in the long grass with a notepad and pencil, making a note every time you hear a roar.
- Set up an audio recorder with a battery, and pick up the memory card every few weeks.
- Transmit audio over a data connection, perhaps a cellular network if available.
All of this work, but there are some major drawbacks:
- Keeping a human on-site is expensive, and there may be safety issues to think about ????
- Driving out to collect a memory card takes time and money, and you only get new data every few weeks.
- Transmitting data uses lots of energy and money, and bandwidth is probably limited in lion territory. You might get the data faster, but you’ll still have to drive out and change the battery.
In addition to these points, counting lion roars in a week’s worth of audio recordings is really boring and costs precious funds. To relieve the tedium, you could train a machine learning model to recognize lion roars in the recordings and count them automatically. To do this, you’d collect a set of labelled data, feed it into an algorithm, and create a model that can spot roars in audio.
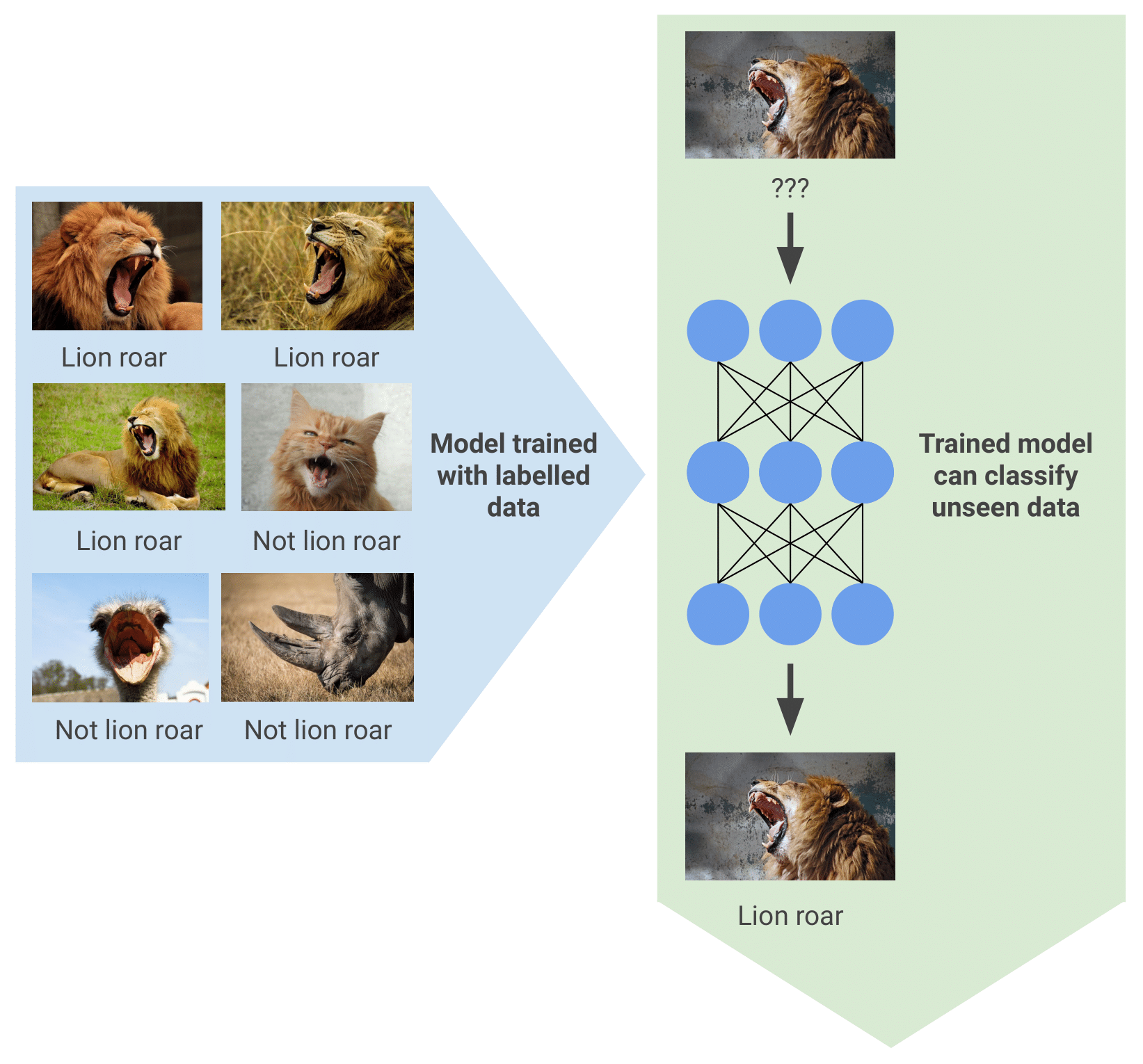
This sounds like a great solution! We solve some real problems and end up with a cheaper, more reliable solution than what we had before.
But there’s some hope. In the past, machine learning models have had to live on big, powerful hardware, so they could only be run on a server in the lab. However, in recent years, machine learning algorithms and low-power hardware have evolved to the point that it’s possible to run sophisticated models on embedded devices.
What if we took our lion roar counting model and deployed it to an embedded device, out in the field? Here are some of the benefits:
- Instead of streaming all the audio via an expensive high-bandwidth connection, our device could count how many roars it hears and send an hourly total via low-power, long-range radio, like LoRa.
- There’d be no need to store the audio or collect a memory card since the number of roars is all we need.
- The device could be cheap and extremely low power, running for years from a single battery.
- Nobody would have to listen to a 100-hour wildlife mixtape.
This sounds like a great solution! We solve some real problems and end up with a cheaper, more reliable solution than what we had before.
But machine learning is an intimidating subject. It’s highly technical, involves a lot of new concepts, and there are a bunch of pitfalls that make it easy to train a model that seems useful, but doesn’t do the job.
Even more, writing machine learning code that runs on embedded devices is hard. In addition to needing knowledge of machine learning and signal processing algorithms, you’ll often be running at the limits of the hardware, and you’ll need to use every trick in the book to squeeze out all of the performance you can for a given type of chip.
When we were writing the TinyML book, I realized that while it’s easy for anyone to get started learning machine learning on embedded devices, it’s a lot harder to build something ready for production. For the average engineer—focused on solving real-world problems—there just aren’t enough hours in the day to spend studying machine learning, let alone optimizing low-level ML code for specific microcontroller architectures. Machine learning sounds like a great solution, but it requires a huge investment to learn and use.
This is why I’m so excited about Edge Impulse (in fact, so much so that I joined the team). It’s a set of tools that takes care of the hairy parts of machine learning, letting developers focus on the problem they are trying to solve. Edge Impulse makes it easy to collect a dataset, choose the right machine learning algorithm, train a production-grade model, and run tests to prove that it works. It then exports the whole thing as an efficient, highly optimized C++ library designed to drop easily into your project.
Using Edge Impulse, the steps for creating our roar-counting model are simple:
- Collect a small amount of audio data, labeled with “roar” or “not roar”. Even just a few minutes is enough to get started.
- Upload the data to Edge Impulse using the Edge Impulse CLI.
- Follow the instructions to train a simple model.
- Add more data and tweak the model’s settings until you get the level of accuracy you need.
- Export the model as a C++ library and add it to your embedded project.
The whole process is quick enough to run through in a few minutes, and you don’t have to visit the African Savanna. Instead, you can step through this tutorial, which is also available in video form:
Since you may lack any lions, the tutorial has you train a model that can recognize household sounds: namely, the sound of running water from a faucet. The model you’ll train is around 18kb in size, which is mind-blowingly small for something so sophisticated and leaves a lot of space for your application code.
If you have an STM32 IoT Node Discovery Kit board, you can capture your own dataset over WiFi or serial. If you don’t, or while you’re waiting for one to arrive, you can download a pre-built dataset collected from my Sunnyvale apartment.
Beyond lions and faucets, there are a huge range of applications for TinyML. Imagine tiny devices that can recognize speech commands (there’s a dataset for that one, too), hear when machines are malfunctioning, and understand the activities happening in a home based on the ambient sounds that are present. The best part is that with inference on-device, user privacy is protected—no audio ever needs to be sent to the cloud.
By making it easy for any developer to build machine learning applications, Edge Impulse is opening up the field for everyone to turn their amazing ideas into hardware. And since we’re continually improving our platforms as the technology evolves, everyone will benefit from the latest production-ready algorithms and techniques.
It’s an exciting time to be an embedded engineer. We’d love to hear what you’re planning to build! Try our audio classification tutorial, and let us know what you think in the comments, on our forum, and on the @edgeimpulse Twitter.
Daniel Situnayake (@dansitu), Founding TinyML Engineer at Edge Impulse