
See the EON Compiler (RAM Optimized).
At Edge Impulse we enable developers to build and deploy machine learning models that run on embedded devices. From machines that detect when they’re going to break to devices that can hear water leaks to camera traps that spot elephant poachers. With memory being very scarce on many of these devices - a typical device might have less than 128K of RAM - we’re happy to announce our new Edge Optimized Neural (EON™) Compiler, which lets you run neural networks in 25-55% less RAM, and up to 35% less flash, while retaining the same accuracy, compared to TensorFlow Lite for Microcontrollers.
The EON Compiler is now available for all Edge Impulse projects - whether you’re building models based on vibration, audio, vision, or your own sensors - and is automatically enabled on all supported targets on the Deployment page of the Edge Impulse Studio. Take your trained project, select either the C++, Arduino, or WebAssembly library deployment option, and click Build. We’ll then take your ML models, compile them with EON, combine them with our SDK and DSP code, and give you a library that you can easily integrate into your project. Like all models that you create in Edge Impulse, the resulting library is royalty-free and delivered as source code.
Here’s an example of the difference EON makes on a typical model in Edge Impulse. Below you’ll see the time per inference, RAM, and ROM usage of a keyword spotting model with a 2D convolutional neural network, running on a Cortex-M4F. At the top: EON, at the bottom: the same model running using TensorFlow Lite for Microcontrollers.
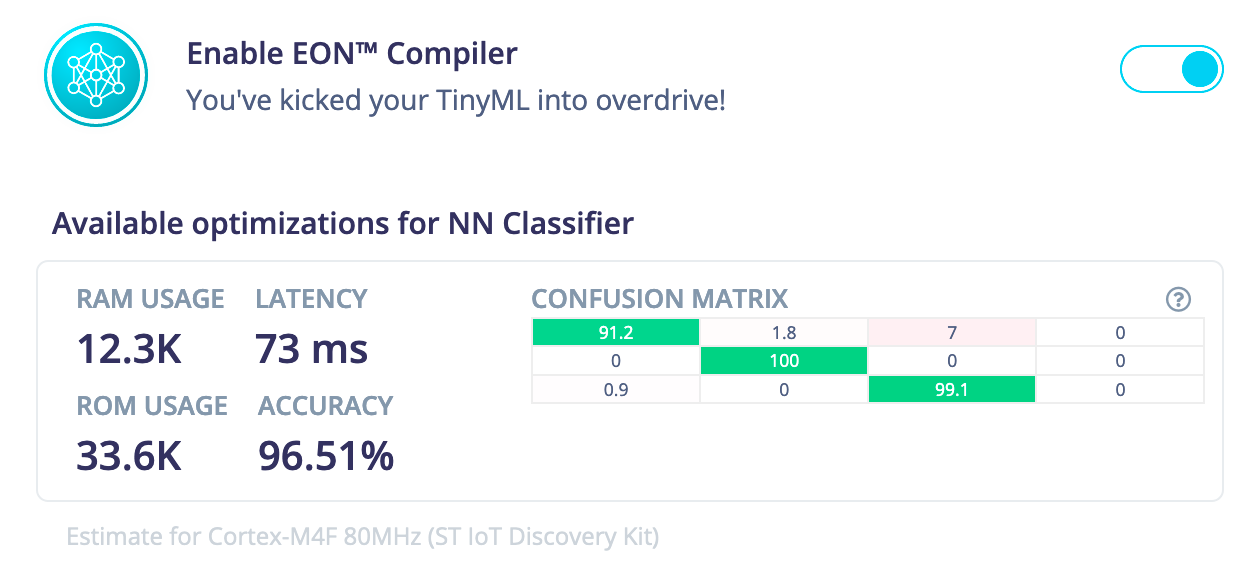
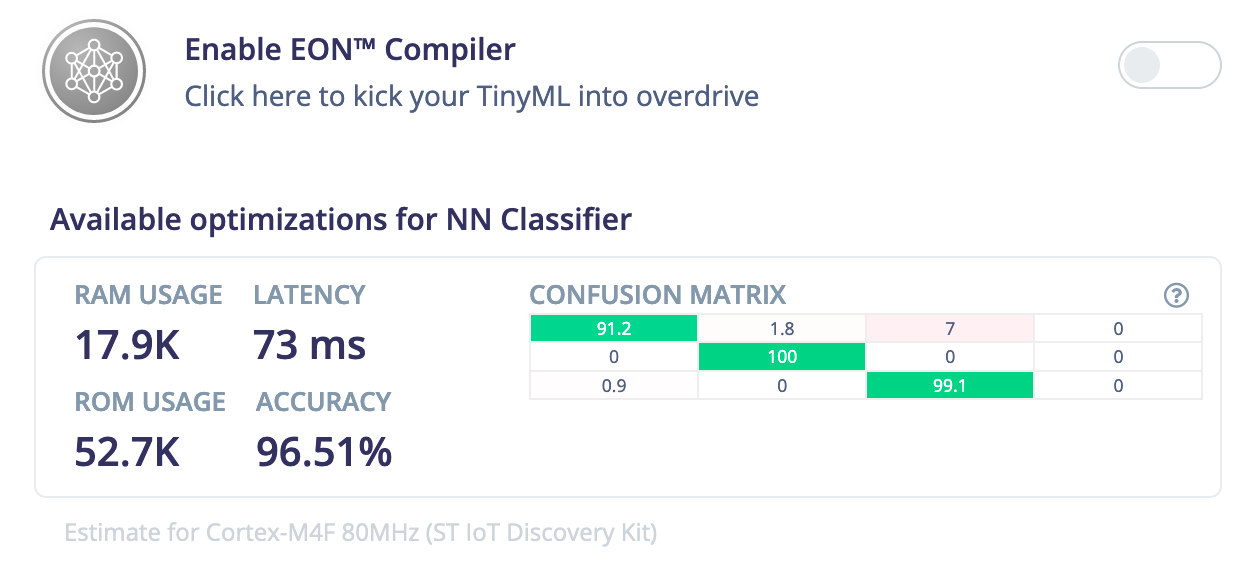
For the quantized model we see a decrease of 32% of RAM usage, and 37% of ROM usage - while keeping the inferencing speed and accuracy exactly the same.
Wait, how does this work?
EON achieves its magic by compiling your neural networks to the C++ source code. This is different than other embedded neural network runtimes, like TensorFlow Lite for Microcontrollers, that have a generic interpreter, and then load your model at runtime. By compiling the neural network to source code you thus don’t need the interpreter, can more easily shift data into ROM, and the linker knows exactly which operations are being used, being able to eliminate a lot more code.
That does not mean that EON is a completely new runtime. We still use TensorFlow Lite for Microcontrollers under the hood and are thus being able to use (and contribute to) the excellent work that the wider community has been doing on this project. This is also why the latency numbers in the example above are exactly the same - we’re using the same kernels and optimizations.
EON is partly based on the work by the Interpreter-less Code Generation for TensorFlow Lite for Microcontrollers working group and their reference implementation and we’ll be contributing our code back to those projects in the next weeks.
Show me some more numbers!
As part of the EON release, we’ve updated all RAM and ROM calculations for Edge Impulse projects, and these are now based on actually compiled binaries. So if you’re curious about memory usage for your specific model, head to your project’s Deployment page.
Here are numbers on inferencing time, RAM, and ROM usage on some typical models in Edge Impulse. These were collected on the ST IoT Discovery Kit (Cortex-M4F 80MHz, 128K RAM) and the STM32F746G-DISCO (Cortex-M7 216MHz, 320K RAM) - both using fully quantized neural networks.
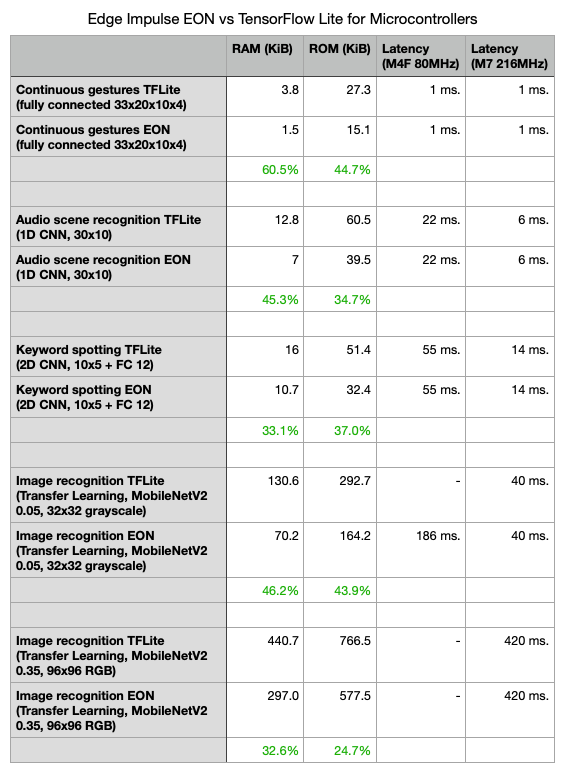
Some notes on the benchmarks:
- The memory usage numbers exclude boot code, peripheral drivers, print, and memory tracking functions to keep the comparison fair.
- The models were compiled using Mbed OS 6.2 in bare-metal mode, compiled with a release profile.
- The TensorFlow Lite for Microcontrollers models had only the required ops loaded (otherwise flash usage shoots up). This is automatically done from Edge Impulse.
- These models use CMSIS-NN kernels to speed up inference times. CMSIS-NN is automatically loaded on compatible MCUs in Edge Impulse.
- This only includes information for the neural networks and excludes any DSP code or other Machine Learning models that you can build with Edge Impulse. See Inference performance metrics in the docs for more information.
Exciting times ahead
This marks a very exciting release. Memory is one of the scarcest resources on many microcontrollers, and EON gives developers an option to significantly reduce RAM and ROM on real machine learning models without losing accuracy or increasing latency. We’re also very excited that we managed to keep EON fully compatible with the wide TensorFlow Lite for Microcontrollers ecosystem. And we’ll keep working very closely with Google and Arm on getting the best performance out of general-purpose MCUs - whether it’s running vibration analysis on a Cortex-M0+, classifying audio on a Cortex-M4F, or recognizing images on even faster MCUs.
EON was built for general-purpose MCUs - but naturally, that’s not the only option to deploy your machine learning model. Silicon vendors are increasingly releasing specialized silicon and neural network accelerators, and we’re working closely together to support these on Edge Impulse. For example, on the Eta Compute’s ECM3532 we automatically offload all neural network operations to the DSP, for the lowest power consumption and fastest inference time.
Excited? You can start making your embedded devices smarter today. Edge Impulse is free for developers, you can capture data from any device, and deploy the resulting ML model on anything with a C++ compiler. And you can even build your first ML model - using the accelerometer, microphone or camera - with your mobile phone. Get started here.
Jan Jongboom is the CTO and co-founder of Edge Impulse. Special thanks to Ajay Gopi for his work on the EON Compiler over the summer.