
Modern commercial security systems generally lack the intelligence to begin recording a video based on information gained through acoustic events. For battery-powered devices like the Ring doorbell camera, this results in lost battery life both in the short-term, by needing to swap out and charge the battery frequently, and long term due to overall cell degradation from repeated deep discharges during a short time frame.
[Note: This blog and the information contained in it is for illustrative and educational purposes only]
Even for devices with AC mains power this "blind spot" still results in too many false positives, because if someone wants to review motion-triggered footage they have to sift through countless videos of trees blowing in the breeze or dozens of other false triggers, when they really only care about capturing videos of real people, pets, or wildlife. Similarly, these existing products and their associated platforms also lack the ability to discern "dangerous" from "safe" scenes on edge devices without needing to "phone home" and utilize intelligence in the cloud.
To demonstrate a better approach to this, I developed a hybrid system that combines existing security equipment with an edge AI platform like the Innodisk APEX-A100 or other Qualcomm Dragonwing™ IQ8 and IQ9-based devices to run a set of AI models that intelligently activates recording and quickly analyzes the contents locally for anything of interest. I call this the Edge Aware Real-Time Security (EARS).
There are limitless possibilities for various sounds to trigger a recording and subsequent vision analysis of detected objects of interest. The configuration used for this project continuously listens for firearm activity, detects if there is a person, then prompts the local Vision Language Model (VLM) to determine if that individual is dangerous or not. All firearms in this publication have been blurred for the sake of professionalism.
Here's how it works.

Test Setup Materials
- Innodisk APEX-A100 running Ubuntu 24.04
- Ring camera: any model (pictured: Indoor Cam, 2nd gen)
- Wired IP camera for generic RTSP access (pictured: Reolink CX820)
- FIFINE condenser microphone for external mic implementation
- Parabolic microphone for initial testing
- Creative Labs Soundblaster Pro (due to issues using the on-board sound card)
The parabolic (directional) microphone that I purchased years ago for bird-watching and originally intended to use here didn’t work out, because its gain controls are limited and despite tuning the USB sound card capture levels; it was still too finicky to get consistent results between vocal music and firearm activity. The USB condenser microphone, however, reliably distinguished firearms from white background noise/hum and music so that was used for the external microphone option. The RTSP streams expose audio as well, so the simplest use case for the majority of development and testing was to just route those through a loopback audio device so that the audio impulse runner could utilize them as inputs.
Block Diagram
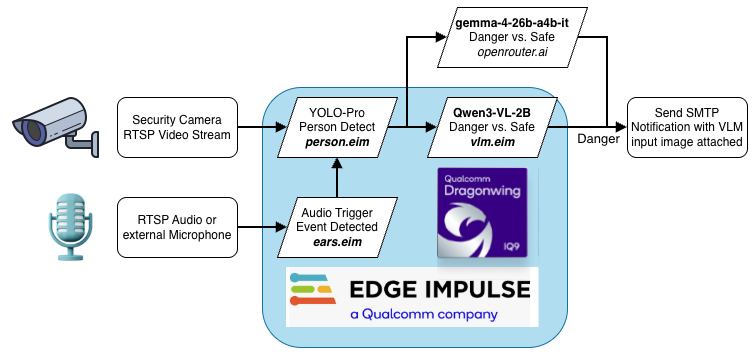
Software Flow
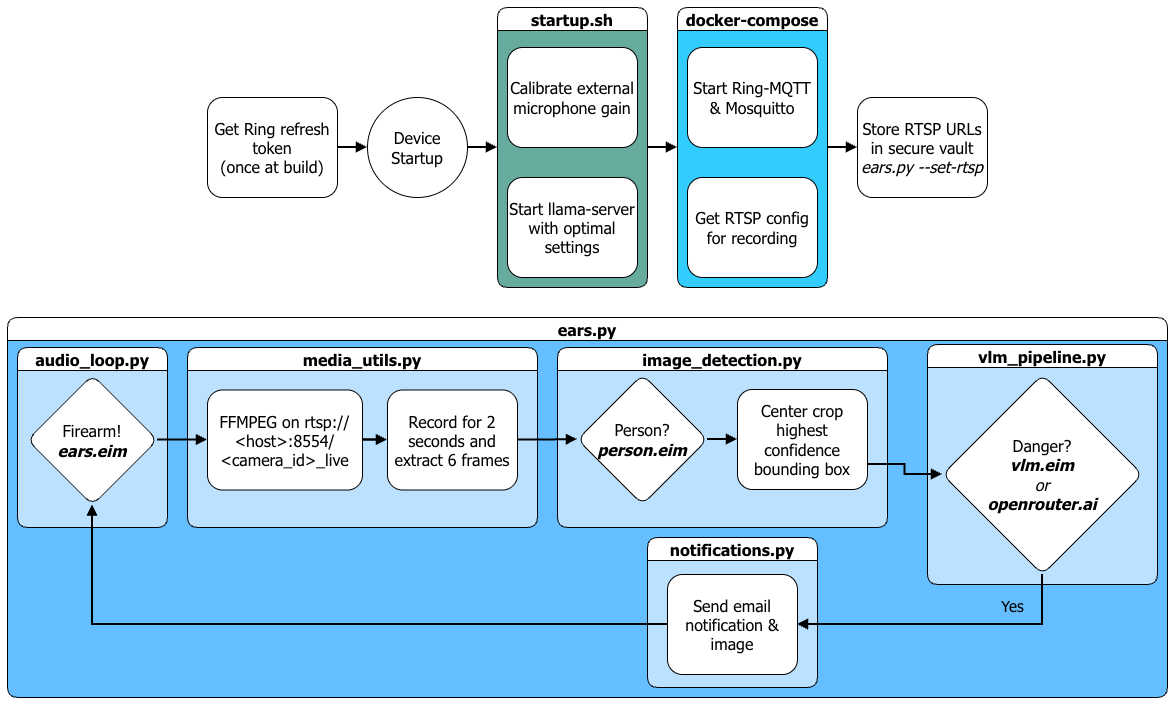
Project Description
Using a Vision Language Model feature in Edge Impulse (look for more about this soon), this entire solution is possible using two distinct models developed in Edge Impulse platform, and a third that deploys from the same place, to wrap our standard .eim model interface around the Qwen3-VL model running concurrently through llama.cpp. The first impulse is an audio classifier that uses public and allowed-for-commercial-use datasets of firearm activity and common background noises, such as vehicles and music, to accurately detect sounds from firearms and trigger the subsequent stages of the detection pipeline.
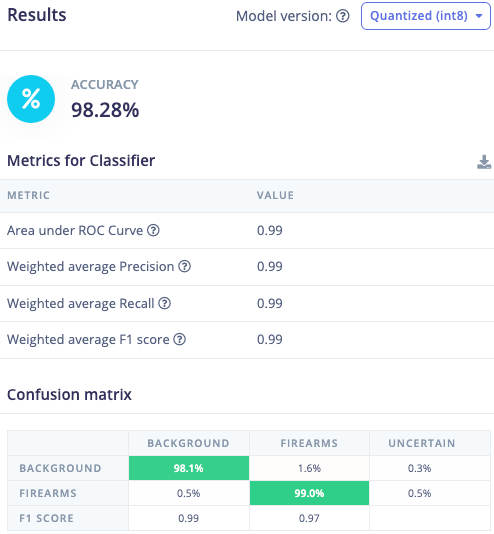
The second impulse uses images from the COCO2014 dataset, which were auto-labeled for detecting people using the Edge Impulse AI-labeling tools and trained using our new YOLO-Pro object detection model.
The models work in sequence: When the audio model detects firearm activity, an RTSP connection to the local Ring camera is enabled via ring-mqtt (or using an RTSP URL for any IP camera that supports it) to capture a video and extract frames to check for people, and if it detects anyone, then the highest-confidence bounding box is cropped as a square centered around the box (to ensure any weapons are included), resized to 160x160 and then passed as an input to the Vision Language Model.

The last and final stage takes the padded and cropped person and prompts the locally running Qwen3-VL-2B model:
“Analyze the image.
If it contains anything dangerous respond with label danger.
If it contains a safe environment respond with label no_danger.
If none of the above apply, respond with label no_danger.”
(Note: The Edge Impulse Platform only loads the 8 Billion parameters version of the VLM for testing purposes but you’re able to use the smaller parameters versions (4B & 2B) of the same model provided you recognize the caveat that actual performance should be thoroughly tested on device and the more complex the prompt the less likely a smaller model will perform as adequately as the data in the studio tests.)

Results
The Qwen3-VL-2B model runs via llama.cpp’s llama-server, with the language portion of the VLM at 4-bit quantization for performance improvements, and it’s able to generate a response for a 160x160 image in about 4 seconds on a Dragonwing IQ-9075. On average, the entire pipeline takes 10 seconds from firearm activity to email notification of danger displaying the cropped image that was sent to the VLM for analysis. For comparison, when a cloud model was used via openrouter.ai the total turnaround time ranged anywhere from 7 seconds up to 23 seconds during peak demand times or low network reliability, showing how the small and inconsistent increase in speed that comes with cloud AI can affect the reliability and privacy that are otherwise preserved when edge AI is used instead.
One could also use both VLM paths every time and only send a danger alert if both models independently flag the person as dangerous, though that was not implemented in this project. This setup was extensively tested with a person in a dark hoodie under various lighting conditions and only when a firearm was visible did the VLM indicate danger, so just a sketchy looking demeanor is not enough by itself to be considered dangerous.
Reolink’s CX820 Power-over-Ethernet IP camera had a hard time focusing on a printed image less than 2 feet away, but even with the slight blurring the results were still consistent, showing just how robust the multimodal VLM is at distinguishing dangerous people.


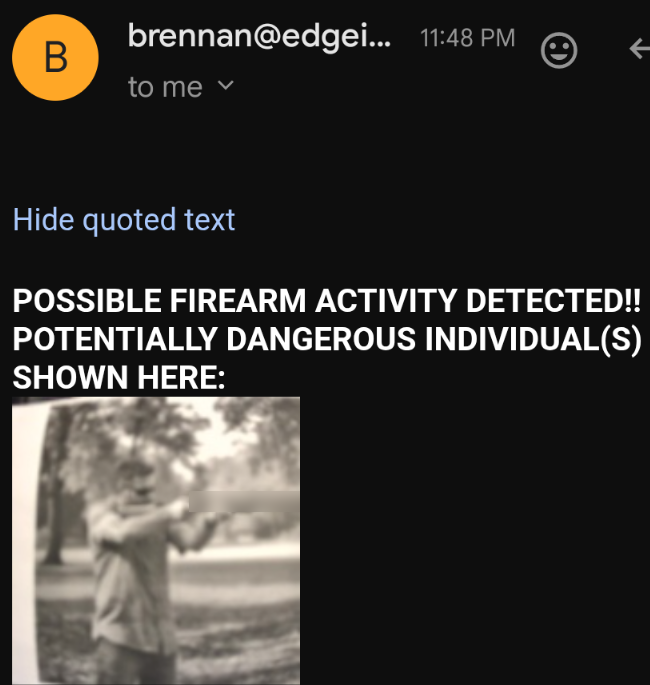
Result (3 ms., delta 303 ms) background: 0.04 firearms: 0.95
Firearm activity detected! Recording rtsp clip...
Recording clip to rtsp-videos/rtsp_clip_20260423-062755.mp4...
Recording complete.
running image classification on rtsp-frames/rtsp_clip_20260423-062755/frame_00002.jpg
Time from detection start to bounding box output: 168 ms
Found 1 bounding boxes (1 ms.)
person (0.94): x=126 y=122 w=57 h=114
Loaded runner for "test / vloom"
Result (2 ms.) danger: 1.00 no_danger: 0.00
HTTP 202
Result (2 ms., delta 12511 ms) background: 1.00 firearms: 0.00
Using the gemma-4-26b-a4b-it model via openrouter.ai for danger analysis shaves 5–6 seconds off but does trade-off the risk that cloud services aren’t as reliable as on-device edge AI so the best option would be to either use the local VLM as a fallback if the cloud path times out or, as previously stated, utilize both in tandem to reach a unanimous decision.Result (3 ms., delta 280 ms) background: 0.00 firearms: 0.99
Firearm activity detected! Recording rtsp clip...
Recording clip to rtsp-videos/rtsp_clip_20260423-061345.mp4...
Recording complete.
running image classification on rtsp-frames/rtsp_clip_20260423-061345/frame_00002.jpg
Time from detection start to bounding box output: 176 ms
Found 1 bounding boxes (1 ms.)
person (0.94): x=131 y=118 w=57 h=118
Using OpenRouter model 'google/gemma-4-26b-a4b-it' for VLM classification
OpenRouter danger label: danger
HTTP 202
Result (3 ms., delta 7535 ms) background: 1.00 firearms: 0.00
The Ring camera had better focus on the printed out synthetically generated test image, and similar response times.


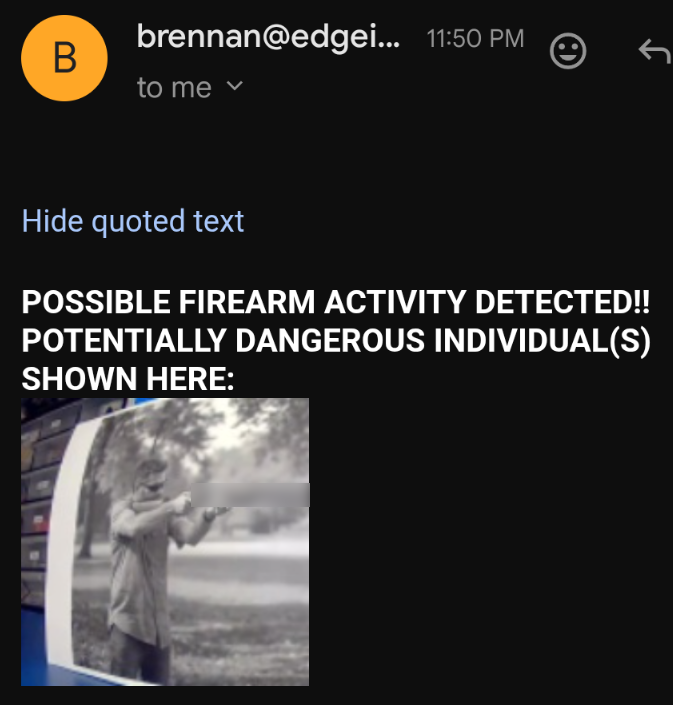
Result (3 ms., delta 300 ms) background: 0.04 gunshots: 0.95
Gunshot detected! Recording rtsp clip...
Recording clip to rtsp-videos/rtsp_clip_20260423-062525.mp4...
Recording complete.
running image classification on rtsp-frames/rtsp_clip_20260423-062525/frame_00002.jpg
Time from detection start to bounding box output: 81 ms
Found 1 bounding boxes (1 ms.)
person (0.78): x=87 y=96 w=61 h=122
Loaded runner for "test / vloom"
Result (2 ms.) danger: 1.00 no_danger: 0.00
HTTP 202
Result (2 ms., delta 13338 ms) background: 1.00 gunshots: 0.00
Ring & Cloud VLM:
Result (3 ms., delta 276 ms) background: 0.04 firearms: 0.95
Firearm activity detected! Recording rtsp clip...
Recording clip to rtsp-videos/rtsp_clip_20260423-062221.mp4...
Recording complete.
running image classification on rtsp-frames/rtsp_clip_20260423-062221/frame_00002.jpg
Time from detection start to bounding box output: 105 ms
Found 1 bounding boxes (1 ms.)
person (0.77): x=91 y=100 w=71 h=114
Using OpenRouter model 'google/gemma-4-26b-a4b-it' for VLM classification
OpenRouter danger label: danger
HTTP 202
Result (3 ms., delta 5390 ms) background: 1.00 firearms: 0.00
Final thoughts
This specific application is just one possibility for combining audio, image, and vision-language models to improve and augment existing computer vision security systems with EARS so they can hear important events and identify them right on the edge.
- Detecting revving engines and use OCR to get the license plate plus the VLM to immediately identify the make and model of the offending vehicle
- System cameras capture video after a glass break event and send frames to a VLM running on the camera’s silicon itself or networked gateway to check for signs of forced entry or burglary
- Monitoring a public area with a keyword spotter for sounds of distress and run a person detection model, combine bounding boxes to encompass everyone, then pass that to the VLM prompting, “Are these people having a public disturbance or are they ambivalent towards each other?”
- A significant audible event occurring underwater can be picked up with arrays of specialized microphones which can trigger video and object detection and then identify the source and potential species or equipment involved
Have a similar use case in mind? Reach out and we can assess its viability.
Qualcomm-branded products are products of Qualcomm Technologies, Inc, and/or its subsidiaries.